Содержание
- 1 Как проверить индексацию сайта
- 2 Как контролировать индексацию
- 3 Как ускорить индексацию
- 4 Вывод
- 5 Почему при индексации стоит, прежде всего, ориентироваться на Гугл и Яндекс
- 6 Пошаговая инструкция по настройке индексации
- 7 Другие способы настройки индексации
- 8 Как происходит процесс индексирования
- 9 Robots.txt
- 10 Дубли
- 11 Неприятности, к которым приводят дубли
- 12 Зеркала сайта
- 13 Переезд сайта на новый домен
- 14 Ошибки при работе с зеркалами
- 15 Полезные ссылки в работе:
- 16 Ответы на вопросы
У каждой поисковой системы – свой набор ботов, выполняющих разные функции. Вот пример некоторых роботов «Яндекса»:
- Основной робот.
- Индексатор картинок.
- Зеркальщик (обнаруживает зеркала сайта).
- Быстробот. Эта особь обитает на часто обновляемых сайтах. Как правило – новостных. Контент появляется в выдаче практически сразу после размещения. При ранжировании в таких случаях учитывается лишь часть факторов, поэтому позиции страницы могут измениться после прихода основного робота.
У «Гугла» тоже есть свой робот для сканирования новостей и картинок, а еще – индексатор видео, мобильных сайтов и т. д.
Скорость индексирования новых сайтов у разных ПС отличается. Каких-то конкретных сроков здесь нет, есть лишь примерные временные рамки: для «Яндекса» – от одной недели до месяца, для Google – от нескольких минут до недели. Чтобы не ждать индексации неделями, нужно серьезно поработать. Об этом и пойдет речь в статье.
Сперва давайте узнаем, как проверить, проиндексирован ли сайт.
Как проверить индексацию сайта
Проверить индексацию можно тремя основными способами:
- Сделать запрос в поисковик, используя специальные операторы.
- Воспользоваться инструментами вебмастеров (Google Search Console, «Яндекс.Вебмастер»).
- Воспользоваться специализированными сервисами или скачать расширение в браузер.
Поисковые операторы
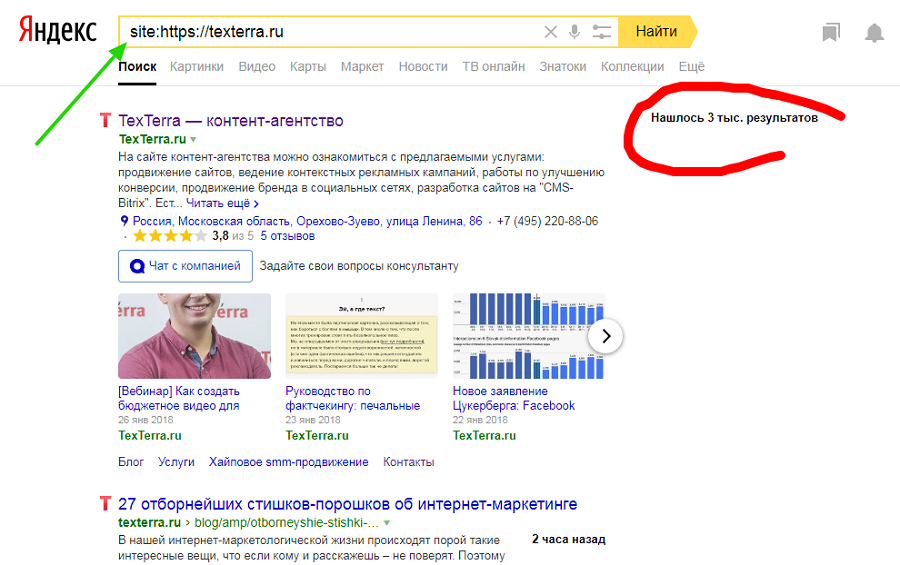
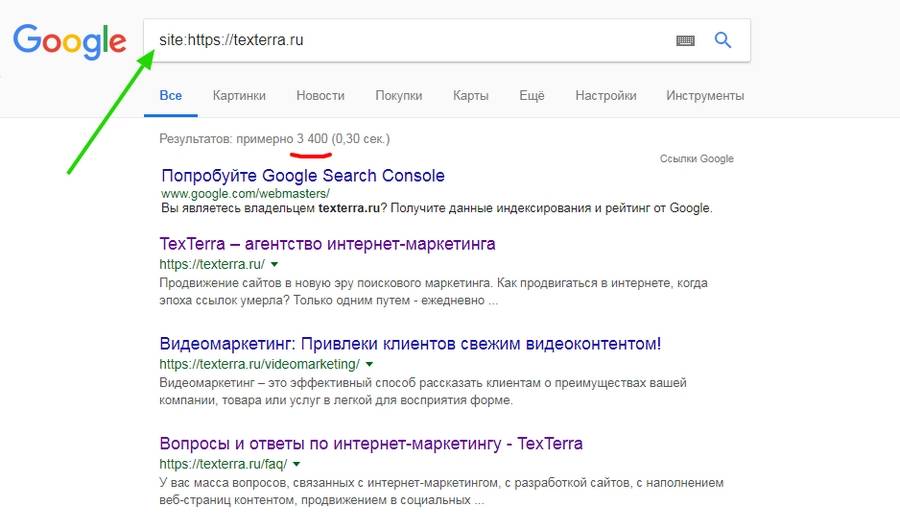
Быстро и просто примерное количество проиндексированных страниц можно узнать с помощью оператора site. Он действует одинаково в «Яндекс» и «Гугл».

Сервисы для проверки индексации
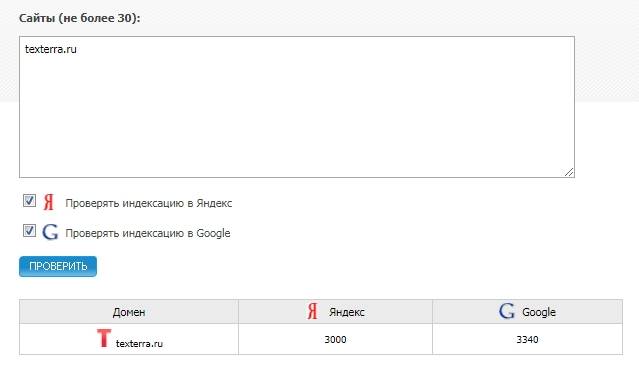
Бесплатные сервисы позволяют быстро узнать количество проиндексированных «Яндексом» и Google страниц. Есть, к примеру, очень удобный инструмент от XSEO.in и SEOGadget (можно проверять до 30 сайтов одновременно).
У RDS целая линейка полезных инструментов для проверки показателей сайтов, в том числе проиндексированных страниц. Можно скачать удобный плагин для браузера (поддерживаются Chrome, Mozilla и Opera) или десктопное приложение.
 Файл robots txt для wordpress правильный и рабочий вариант для всех сайтов
Файл robots txt для wordpress правильный и рабочий вариант для всех сайтов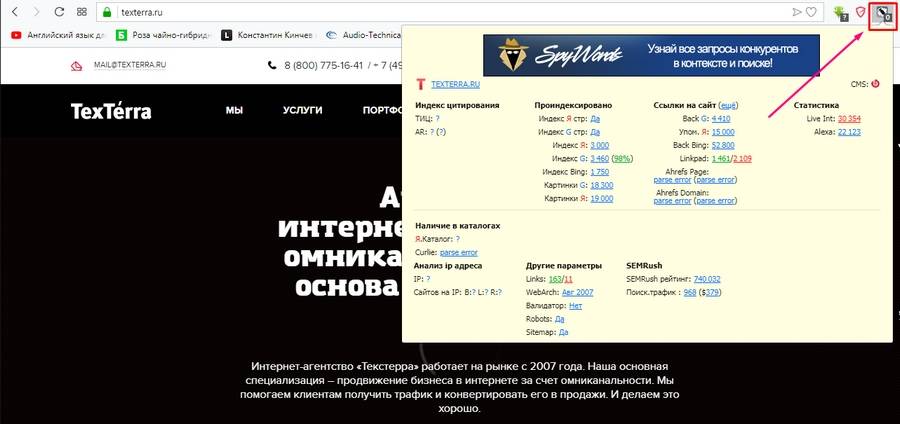
Вообще плагин больше подходит профессиональным SEOшникам. Если вы обычный пользователь, будьте готовы, что эта утилита будет постоянно атаковать вас лишней информацией, вклиниваясь в код страниц, и в итоге придется либо ее настраивать, либо удалять.
Панели вебмастера
«Яндекс.Вебмастер» и Google Search Console предоставляют подробную информацию об индексировании. Так сказать, из первых уст.
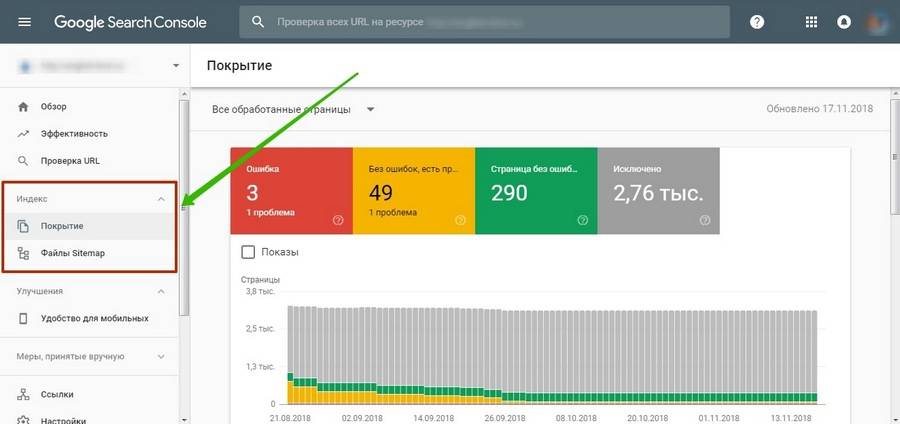
В старой версии GSC можно также посмотреть статистику сканирования и ошибки, с которыми сталкиваются роботы при обращении к страницам.
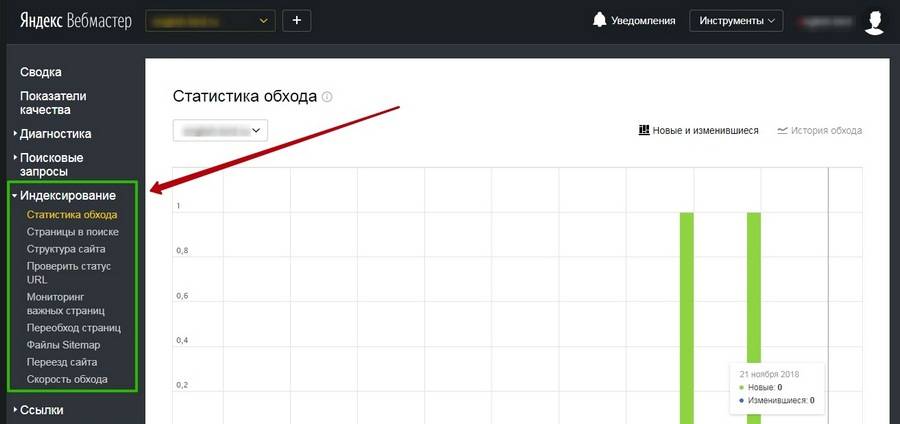
Подробнее о данных об индексировании, представленных в панелях вебмастеров, можно почитать в соответствующих разделах наших руководств по «Яндекс.Вебмастеру» и Google Search Console.
58 самых распространенных ошибок SEO
Как контролировать индексацию
Поисковые системы воспринимают сайты совсем не так, как мы с вами. В отличие от рядового пользователя, поисковый робот видит всю подноготную сайта. Если его вовремя не остановить, он будет сканировать все страницы, без разбора, включая и те, которые не следует выставлять на всеобщее обозрение.
 Конструктор сайтов Tilda: подробный обзор, примеры и отзывы
Конструктор сайтов Tilda: подробный обзор, примеры и отзывыПри этом нужно учитывать, что ресурсы робота ограничены: существует определенная квота – количество страниц, которое может обойти паук за определенное время. Если на вашем сайте огромное количество страниц, есть большая вероятность, что робот потратит большую часть ресурсов на «мусорные» страницы, а важные оставит на будущее.
Поэтому индексированием можно и нужно управлять. Для этого существуют определенные инструменты-помощники, которые мы далее и рассмотрим.
Robots.txt
Robots.txt – простой текстовый файл (как можно догадаться по расширению), в котором с помощью специальных слов и символов прописываются правила, которые понимают поисковые системы.
Директивы, используемые в robots.txt:
|
Директива |
Описание |
|
User-agent |
Обращение к роботу. |
|
Allow |
Разрешить индексирование. |
|
Disallow |
Запретить индексирование. |
|
Host |
Адрес главного зеркала. |
|
Sitemap |
Адрес карты сайта. |
|
Crawl-delay |
Время задержки между скачиванием страниц сайта. |
|
Clean-param |
Страницы с какими параметрами нужно исключить из индекса. |
User-agent показывает, к какому поисковику относятся указанные ниже правила. Если адресатом является любой поисковик, пишем звездочку:
User-agent: Yandex
User-agent: GoogleBot
User-agent: Bingbot
User-agent: Slurp (поисковый робот Yahoo!)
 Максимальное ускорение: что такое турбо-страницы и как их подключить
Максимальное ускорение: что такое турбо-страницы и как их подключитьUser-agent: *
Самая часто используемая директива – disallow. Как раз она используется для запрета индексирования страниц, файлов или каталогов.
К страницам, которые нужно запрещать, относятся:
- Служебные файлы и папки. Админ-панель, файлы CMS, личный кабинет пользователя, корзина и т. д.
- Малоинформативные вспомогательные страницы, не нуждающиеся в продвижении. Например, биографии авторов блога.
- Различного вида дубли основных страниц.
На дублях остановимся подробнее. Представьте, что у вас есть страница блога со статьей. Вы прорекламировали эту статью на другом ресурсе, добавив к существующему URL UTM-метку для отслеживания переходов. Адрес немного изменился, но он все еще ведет на ту же страницу – контент полностью совпадает. Это дубль, который нужно закрывать от индексации.
Не только системы статистики виноваты в дублировании страниц. Дубли могут появляться при поиске товаров, сортировке, из-за наличия одного и того же товара в нескольких категориях и т. д. Даже сами движки сайта часто создают большое количество разных дублей (особенно WordPress и Joomla).
Мы делаем сайты, которые оптимизированы под поисковики и приносят продажи.Подробнее
Помимо полных дублей существуют и частичные. Самый лучший пример – главная страница блога с анонсами записей. Как правило, анонсы берутся из статей, поэтому на таких страницах отсутствует уникальный контент. В этом случае анонсы можно уникализировать или вовсе убрать (как в блоге Texterra).
У подобных страниц (списки статей, каталоги товаров и т. д.) также присутствует постраничная навигация (пагинация), которая разбивает список на несколько страниц. О том, что делать с такими страницами, Google подробно расписал в своей справке.
Дубли могут сильно навредить ранжированию. Например, из-за большого их количества поисковик может показывать по определенным запросам совершенно не те страницы, которые вы планировали продвигать и на которые был сделан упор в плане оптимизации (например, есть усиленная ссылками страница товара, а поисковик показывает совершенно другую). Поэтому важно правильно настроить индексацию сайта, чтобы этой проблемы не было. Как раз один из способов борьбы с дублями – файл robots.txt.
Пример robots.txt для одного известного блога:
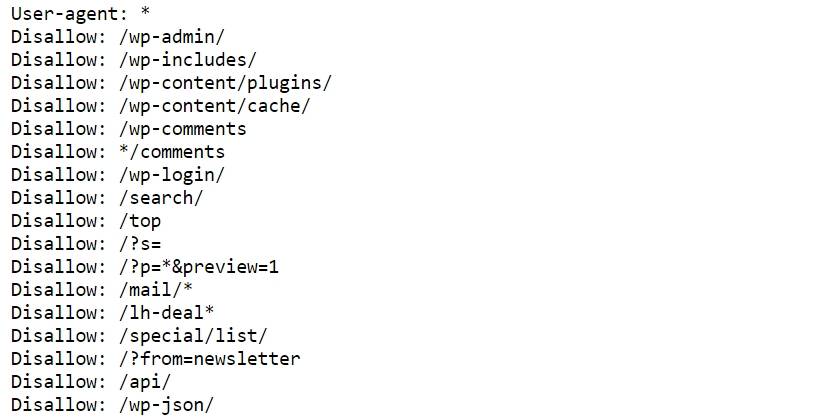
При составлении robots.txt можно ориентироваться на другие сайты. Для этого просто добавьте в конце адреса главной страницы интересующего сайта после слеша «robots.txt».Не забывайте только, что функционал у сайтов разный, поэтому полностью скопировать директивы топовых конкурентов и жить спокойно не получится. Даже если вы решите скачать готовый robots.txt для своей CMS, в него все равно придется вносить изменения под свои нужды.
Давайте разберемся с символами, которые используются при составлении правил.
Путь к определенному файлу или папке мы указываем через слеш (/). Если указана папка (например, /wp-admin/), все файлы из этой папки будут закрыты для индексации. Чтобы указать конкретный файл, нужно полностью указать его имя и расширение (вместе с директорией).
Если, к примеру, нужно запретить индексацию файлов определенного типа или страницу, содержащую какой-либо параметр, можно использовать звездочки (*):
Disallow: /*openstat=
Disallow: /*?utm_source=
Disallow: /*price=
Disallow: /*gclid=*
На месте звездочки может быть любое количество символов (а может и не быть вовсе). Значок $ используется, когда нужно отменить правило, созданное значком *. Например, у вас есть страница eda.html и каталог /eda. Директива «/*eda» запретит индексацию и каталога, и страницы. Чтобы оставить страницу открытой для роботов, используйте директиву «/eda$».
Запретить индексацию страниц с определенными параметрами также можно с помощью директивы clean-param. Подробнее об этом можно прочитать в справке «Яндекса».
Директива allow разрешает индексирование отдельных каталогов, страниц или файлов. Например, нужно закрыть от ПС все содержимое папки uploads за исключением одного pdf-файла. Вот как это можно сделать:
Disallow: /wp-content/uploads/
Allow: /wp-content/uploads/book.pdf
Следующая важная (для «Яндекса») директива – host. Она позволяет указать главное зеркало сайта.
У сайта может быть несколько версий (доменов) с абсолютно идентичным контентом. Даже если у вас домен единственный, не стоит игнорировать директиву host, это разные сайты, и нужно определить, какую версию следует показывать в выдаче. Об этом мы уже подробно писали в статье «Как узнать главное зеркало сайта и настроить его с помощью редиректа».
Еще одна важная директива – sitemap. Здесь (при наличии) указывается адрес, по которому можно найти карту вашего сайта. О том, как ее создать и для чего она нужна, поговорим позже.
Наконец, директива, которая применяется не так часто – crawl-delay. Она нужна в случае, когда нагрузка на сервер превышает лимит хостинга. Такое редко встречается у хороших хостеров, и без видимых причин устанавливать временные ограничения на скачивание страниц роботам не стоит. К тому же скорость обхода можно регулировать в «Яндекс.Вебмастере».
Нужно отметить, что поисковые системы по-разному относятся к robots.txt. Если для «Яндекса» это набор правил, которые нельзя нарушать, то «Гугл» воспринимает его, скорее, как рекомендацию и может проигнорировать некоторые директивы.
В robots.txt нельзя использовать кириллические символы. Поэтому если у вас кириллический домен, используйте онлайн-конвертеры.
После создания файла его нужно поместить в корневой каталог сайта, т. е.: site.ru/robots.txt.
Проверить robots.txt на наличие ошибок можно в разделе «Инструменты» панели «Яндекс.Вебмастер»:
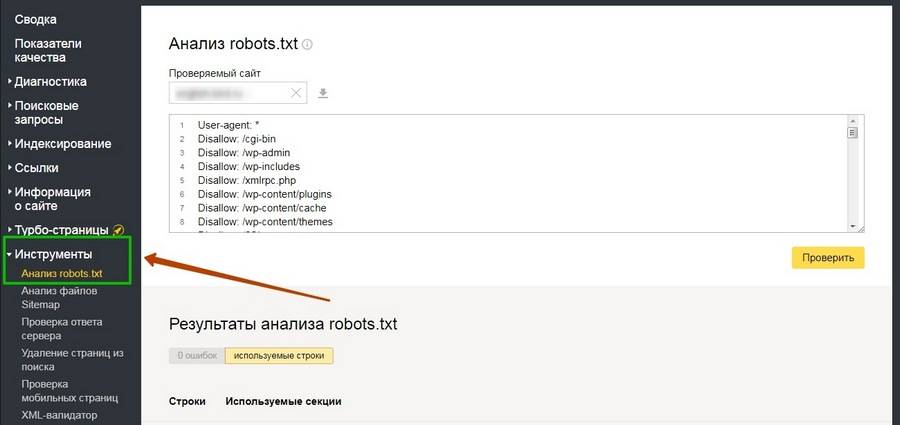
В старой версии Google Search Console тоже есть такой инструмент.
Как закрыть сайт от индексации
Если вам по какой-то причине нужно, чтобы сайт исчез из выдачи всех поисковых систем, сделать это очень просто:
User-agent: *
Disallow: /
Крайне желательно делать это, пока сайт находится в разработке. Чтобы снова открыть сайт для поисковых роботов, достаточно убрать слеш (главное – не забыть это сделать при запуске сайта).
Nofollow и noindex
Для настройки индексации используются также специальные атрибуты и html-теги.
У «Яндекса» есть собственный тег
Проблема в том, что этот тег практически никто кроме «Яндекса» не понимает, поэтому при проверке кода большинство валидаторов выдают ошибки. Это можно исправить, если слегка изменить внешний вид тегов:
текст
Атрибут rel=”nofollow” позволяет закрыть от индексации отдельные ссылки на странице. В отличие от
Кстати, на мега-теге robots стоит остановиться подробнее. Как и файл robots.txt, он позволяет управлять индексацией, но более гибко. Чтобы понять принцип работы, рассмотрим варианты инструкций:
|
индексировать контент и ссылки |
|
не индексировать контент и ссылки |
|
не индексировать контент, но переходить по ссылкам |
|
индексировать контент, но не переходить по ссылкам |
Это далеко не все примеры использования мета-тега robots, так как помимо nofollow и noindex существуют и другие директивы. Например, noimageindex, запрещающая сканировать изображения на странице. Подробнее почитать об этом мета-теге и его применении можно в справке от Google.
Rel=”canonical”
Еще один способ борьбы с дублями – использование атрибута rel=”canonical”. Для каждой страницы можно задать канонический (предпочитаемый) адрес, который и будет отображаться в поисковой выдаче. Прописывая атрибут в коде дубля, вы «прикрепляете» его к основной странице, и путаницы c ee версиями не возникнет. При наличии у дубля ссылочного веса он будет передаваться основной странице.
Вернемся к примеру с пагинацией в WordPress. С помощью плагина All in One SEO можно в один клик решить проблему с дублями этого типа. Посмотрим, как это работает.
Зайдем главную страницу блога и откроем, к примеру, вторую страницу пагинации.

Теперь посмотрим исходный код, а именно – тег с атрибутом rel=»canonical» в разделе
. Изначально он выглядит так:
Каноническая ссылка установлена неправильно – она просто повторяет физический адрес страницы. Это нужно исправить. Переходим в общие настройки плагина All in One SEO и отмечаем галочкой пункт «No Pagination for Canonical URLs» (Запретить пагинацию для канонических URL).
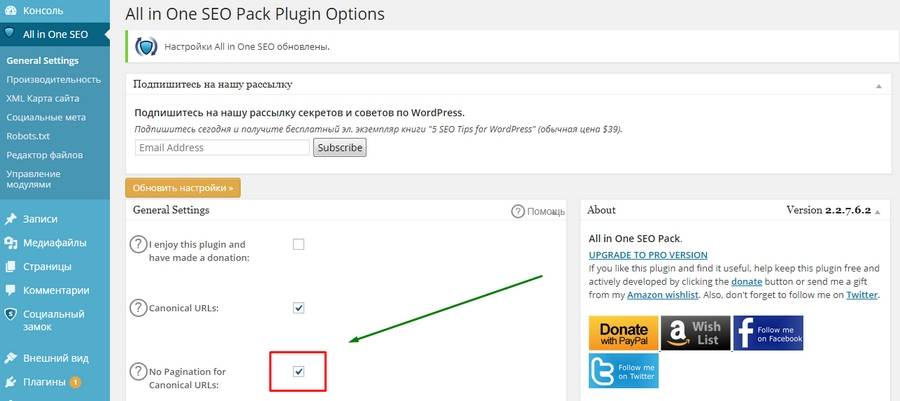
После обновления настроек снова смотрим код, теперь должно быть вот так:
И так – на любой странице, будь то вторая или двадцатая. Быстро и просто.
Но есть одна проблема. Для Google такой способ не подходит (он сам об этом писал), и использование атрибута canonical может негативно отразиться на индексировании страниц пагинации. Если для блога это, в принципе, не страшно, то со страницами товаров лучше не экспериментировать, а использовать атрибуты rel=”prev” и rel=”next”. Только вот «Яндекс» их, по словам Платона Щукина, игнорирует. В общем, все неоднозначно и ничего не понятно, но это нормально – это SEO.
Чек-лист по оптимизации сайта, или 100+ причин не хоронить SEO
Sitemap (карта сайта)
Если файл robots.txt указывает роботу, какие страницы ему трогать не надо, то карта сайта, напротив, содержит в себе все ссылки, которые нужно индексировать.
Главный плюс карты сайта в том, что помимо перечня страниц она содержит полезные для робота данные – дату и частоту обновлений каждой страницы и ее приоритет для сканирования.
Файл sitemap.xml можно сгенерировать автоматически с помощью специализированных онлайн-сервисов. Например, Gensitemap (рус) и XML-Sitemaps (англ). У них есть ограничения на количество страниц, поэтому если у вас большой сайт (больше 1000 страниц), за создание карты придется заплатить символическую сумму. Также получить готовый файл можно с помощью плагина. Самый простой и удобный плагин для WordPress – Google XML Sitemaps. У него довольно много разных настроек, но в них несложно разобраться.
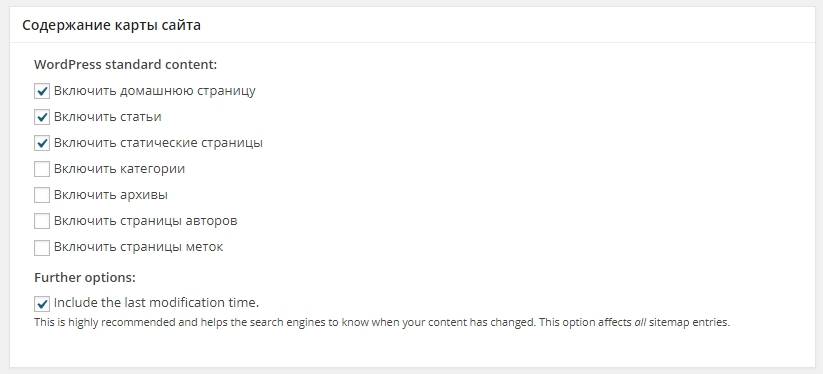
В результате получается простенькая и удобная карта сайта в виде таблички. Причем она становится доступной сразу после активации плагина.
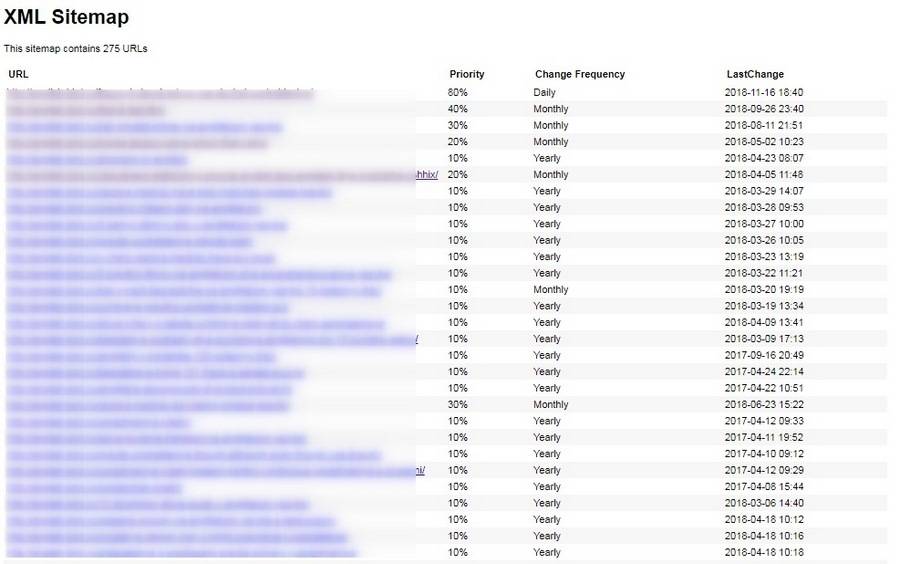
Sitemap крайне полезен для индексации, так как зачастую роботы уделяют большое внимание старым страницам и игнорируют новые. Когда есть карта сайта, робот видит, какие страницы изменились, и при обращении к сайту в первую очередь посещает их.
SEO-оптимизация интернет-магазина: 25 эффективных советов
Если вы создали карту сайта при помощи сторонних сервисов, готовый файл необходимо скачать и поместить, как и robots.txt, в папку на хостинге, где расположен сайт. Опять же, в корневой папке: site.ru/sitemap.xml.
Для удобства желательно загрузить полученный файл в специальный раздел в «Яндекс.Вебмастере» и Google Search Console.
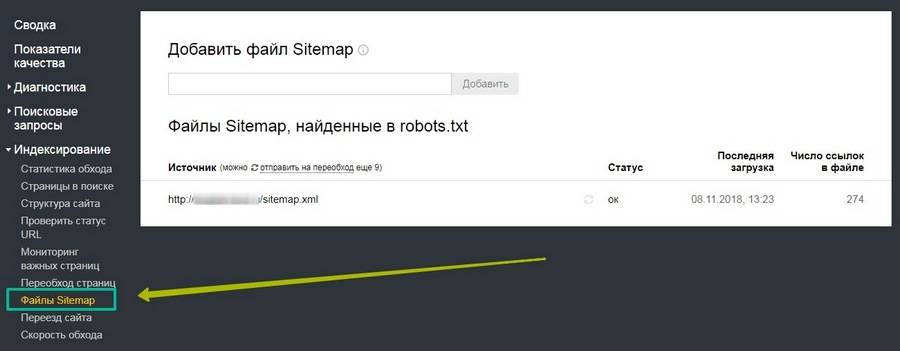
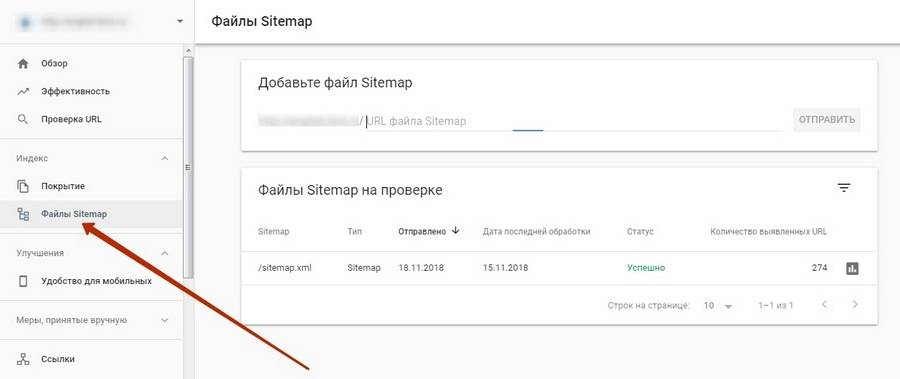
В старой версии инструмент немного отличается.
В «Яндекс.Вебмастере» проверить содержимое карты сайта на наличие ошибок можно в разделе «Инструменты».
Как ускорить индексацию
Поисковые системы рано или поздно узнают о вашем сайте, даже если вы ничего для этого не сделаете. Но вы наверняка хотите получать клиентов и посетителей как можно раньше, а не через месяцы, поэтому затягивать с индексацией – себе в убыток.
Регулярное быстрое индексирование необходимо не только новым, но и действующим сайтам – для своевременного обновления данных в поиске. Представьте, что вы решили оптимизировать старые непривлекательные заголовки и сниппеты, чтобы повысить CTR в выдаче. Если ждать, пока робот сам переиндексирует все страницы, можно потерять кучу потенциальных клиентов.
Вот еще несколько причин, чтобы как можно быстрее «скормить» роботам новые странички:
- На сайте публикуется контент, быстро теряющий актуальность. Если сегодняшняя новость проиндексируется и попадет в выдачу через неделю, какой от нее толк?
- О сайте узнали мошенники и следят за обновлениями быстрее любого робота: как только у вас публикуется новый материал, они копируют его себе и благополучно попадают на первые позиции благодаря более быстрому индексированию.
- На страницах появляются важные изменения. К примеру, у вас изменились цены или ассортимент, а в поиске показываются старые данные. В результате пользователи разочаровываются, растет показатель отказов, а сайт рискует опуститься в поисковой выдаче.
Ускорение индексации – работа комплексная. Каких-то конкретных способов здесь нет, так как каждый сайт индивидуален (как и серверы, на которых они расположены). Но можно воспользоваться общими рекомендациями, которые, как правило, позитивно сказываются на скорости индексирования.
Перечислим кратко, что можно сделать, чтобы сайт индексировался быстрее:
- Указать роботам, что индексировать и что не индексировать. Про robots.txt, карту сайта и все их преимущества мы уже говорили. Если файлы будут составлены правильно, боты быстрее справятся со свалившимся на них объемом новой информации.
- Зарегистрироваться в «Яндекс.Вебмастере» и Google Search Console. Там вы сможете не только заявить о новом сайте, но и получить доступ к важным инструментам и аналитике.
- Обратить внимание на сам сайт. Чтобы роботу (как и пользователям) проще было ориентироваться на сайте, у него должна быть понятная и простая структура и удобная навигация. Сюда же можно отнести грамотную перелинковку, которая может помочь в передвижении по сайту и обнаружении важных страниц. Качество контента тоже может повлиять на скорость индексирования, поэтому лучше выкладывать уникальные тексты, несущие пользу.
- Публикуйтесь на внешних площадках. Многие рекомендуют регистрировать сайты в сервисах социальных закладок, каталогах, «прогонять» по «Твиттеру», покупать ссылки и т. д. Мне в свое время это не помогло – новый сайт индексировался месяц. Но вот ссылки с крупных посещаемых ресурсов (где даже может обитать быстробот) действительно могут помочь. О том, как и где публиковаться, у нас было много статей: «Гостевой постинг: как публиковаться, вставлять ссылки и не платить за это», «Внешний контент-маркетинг: зачем, о чем и куда писать», гайд по линкбилдингу.
- Обновляйте сайт чаще. Если на сайте месяцами не публикуются новые материалы, робот меняет тактику и заходит на сайт реже.
Еще в панелях «Яндекс.Вебмастера» и Google Search Console можно отправлять роботов на конкретные страницы.
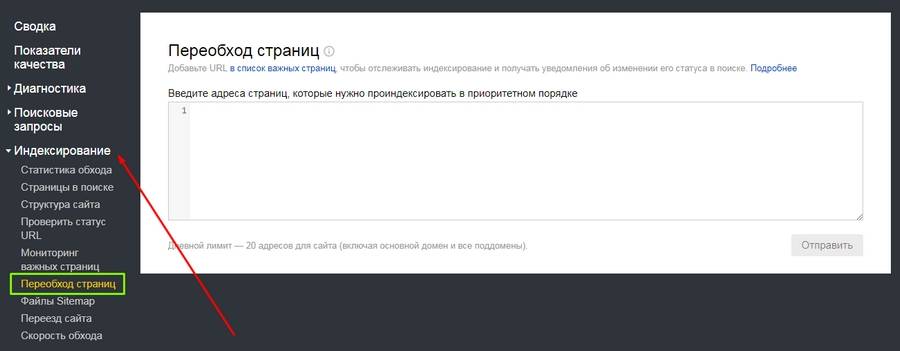
Обратите внимание на то, что отдельные адреса можно добавить в важные, чтобы потом отслеживать их индексирование.
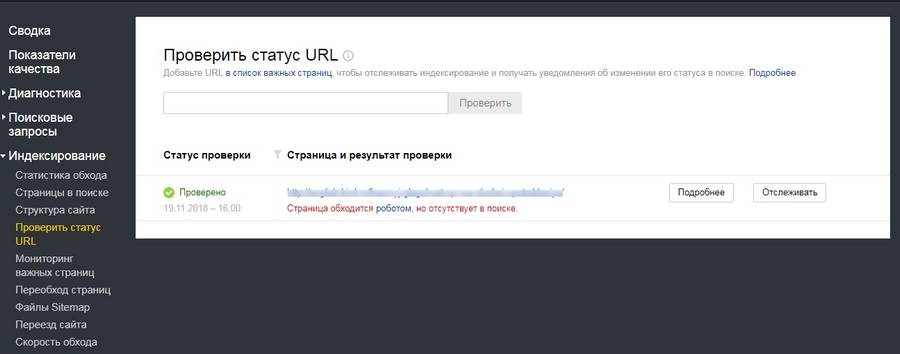
А вот еще одна полезная штука: здесь можно узнать, проиндексирован ли конкретный URL.
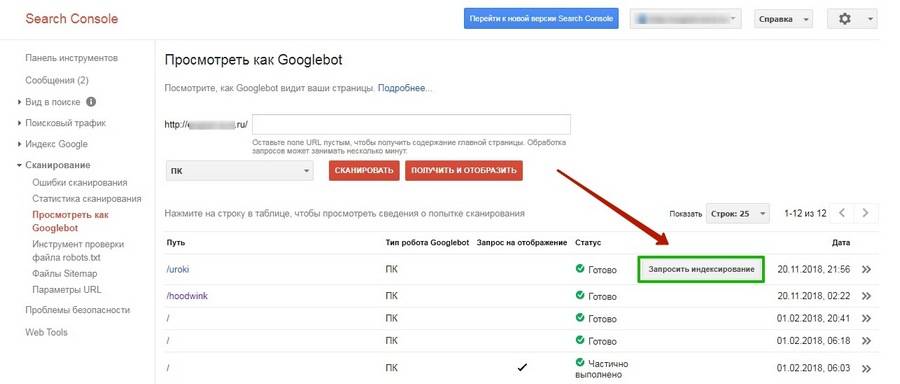
В Google запросить индексирование конкретных страниц можно во вкладке «Посмотреть как Googlebot» (старая версия).
Это, пожалуй, самые основные способы ускорения индексации. Есть и другие, но их эффективность – под вопросом. В большинстве случаев тратить на них время не стоит, если только проиндексировать сайт нужно срочно, и вы готовы испробовать любые способы. В таких случаях лучше читать конкретные кейсы. Например, как проиндексировать сайт в Google в течение 24 часов.
Вывод
Индексация сайта – сложный процесс, с которым поисковые системы далеко не всегда справляются в одиночку. Так как индексирование влияет непосредственно на ранжирование сайта в поисковой выдаче, имеет смысл взять управление в свои руки и максимально упростить работу поисковым роботам. Да, придется повозиться и набить много шишек, но даже такой непредсказуемый зверь как поисковый бот все же может покориться человеку.
 Переходы пользователей на сайты из поисковых систем являются одним из первейших источников получения посетителей, иначе — потенциальных пользователей товара/услуги, представленных на ресурсе. Своевременная индексация информации сайта поисковиками позволяет не потерять своих клиентов. Поэтому действия, связанные с представленностью в поиске, должны носить обязательный первостепенный характер, особенно для сайтов-новичков.
Переходы пользователей на сайты из поисковых систем являются одним из первейших источников получения посетителей, иначе — потенциальных пользователей товара/услуги, представленных на ресурсе. Своевременная индексация информации сайта поисковиками позволяет не потерять своих клиентов. Поэтому действия, связанные с представленностью в поиске, должны носить обязательный первостепенный характер, особенно для сайтов-новичков.
Почему при индексации стоит, прежде всего, ориентироваться на Гугл и Яндекс
Поисковые системы Яндекс и Google зарекомендовали себя как лучшие и, соответственно, популярные поисковые системы.
Это обусловлено тем, что уровень развития основных характеристик В«поисковиковВ» превосходит все остальные представленные на сегодняшний день системы:
- Точность — насколько найденные системой документы соответствуют запросу. Например, при введении пользователем в строку поиска В«купить шубуВ» В«поисковикВ» выводит 90-100% процентов с приведенным невидоизмененным сочетанием этих слов. Чем выше процент схожести, тем лучше.
- Полнота — количество документов, относительно всех имеющихся в сети по этой теме, которые выдает пользователю система. Если всего в сети условно находится 100 документов по вопросу В«Еда для ребенка 1 годаВ», а В«поисковикВ» предоставил к рассмотрению всего 70, полнота будет равна 0,7. В«ВыигрываетВ» система поиска с большим значением.
- Скорость поиска связана с техническими характеристиками и возможностями каждого В«поисковикаВ». Чем она выше, тем больше пользователи будут удовлетворены работой системы.
- Наглядность поиска — это качество представления информации по запросу, подсказки системы относительно тех документов, которые нашлись по запросу. Это наличие упрощающих работу элементов на странице выдачи результатов.
- Актуальность — характеристика, обозначающая временной промежуток между получением информации иВ занесением в базу индекса. У крупных поисковиков существует так называемая В«быстрая базаВ», позволяющая в сжатые сроки индексировать новую информацию.
Кстати бесплатно ускорить индексацию можно, добавив сайт сюда.
Пошаговая инструкция по настройке индексации
Перед тем, как отправить сайт на индексацию поисковыми системами, необходимо произвести предварительную подготовку. Связано это с несколькими моментами:
- Грамотная предварительная работа исключит индексацию роботом поисковой системы лишней или не до конца оформленной и прописанной информации.
- При обнаружении роботом недочетов — непрописанных мета-данных, грамматических ошибок, незакрытых неинформативных ссылок — поисковая система ответит владельцу сайта низким рейтингом, некорректной подачей материала в выдаче и т.п.
- Пока производится подготовительная к демонстрации В«поисковикамВ» работа, необходимо скрыть информацию от роботов и индексации соответствующей записью в файле robots.txt.
Правильная подготовка к индексации будет включать в себя:
1.Разработку мета-тегов, description и title страниц:
- Title должен содержать не более 60 знаков. Это основной заголовок страницы и самый важный из тегов.
- Description состоит из читабельных фраз, позиционирующих данную страницу, то есть необходимо прописать основные тезисы, о чем именно пойдет речь в данном материале.
- Тег keywords предполагает прописывание всех возможных слов по данному вопросу. В последнее время ценность этого тега уменьшилась в глазах поисковых систем, поисковых подсказок.
- Мета-тег revisit (или revisit-after) будет говорить о том сроке, когда планируются обновления сайта, это своего рода просьба-рекомендация оптимизатора для робота, указывающая оптимальный промежуток времени до следующей проверки ресурса.
Этот тег можно использовать только при максимальной уверенности в результате. Иначе это действие может иметь лишь обратный эффект.
2. Сокрытие внутренних и неинформативных разделов сайта. Производится эта робота также в файле robots.txt. В«ПоисковикВ» считает такого рода информацию В«сорнойВ», а потому это будет минусом в процессе проверки ресурса.
3. Необходимо также скрыть и ссылки на разделы служебного характера, которые расположены в содержимом сайта. Для этого используются командыВ noindexВ (для Яндекса) иВ nofollowВ (для всех В«поисковиковВ»).
4. Незакрытые внешние ссылки на другие сайты могут привести к снижению веса сайта. Поэтому их тоже необходимо скрывать от роботов.
5. К выделению ключевых слов и основных моментов жирным необходимо относиться аккуратно, поскольку поисковая система расценивает эти слова как самые важные, что не всегда является так фактически.
6. Все имеющиеся изображения необходимо подписать тегом alt.
7. Необходимо проверить тексты на количество ключевых слов и оборотов в тексте, чтобы робот не проигнорировал информацию в связи с высоким показателем тошноты текста.
8. Обязательным пунктом перед подачей заявки в поисковые системы на индексацию ресурса является проверка орфографии, ошибок грамматического и стилистического характера. При наличии таковых в дескрипшн система выдаст информацию именно в таком виде, что может отсеять большой процент желающих посетить сайт еще на этапе выдачи по запросу.
Для того, чтобы ресурс вышел в числе других в выдаче по поисковому запросу пользователя, необходимо настроить индексацию в основных используемых поисковых системах:
1. Google Search Console:
- Форма добавления ресурса доступна по ссылкеВ https://www.google.com/webmasters/tools/submit-url.В
- Для использования сервиса нужно войти в систему со своего аккаунта Google.
- Появится окно, в которое необходимо ввести адрес ресурса, который требует индексации.
- Подтверждением владения сайтом будет загрузка файла HTML в корень ресурса.
- Система Google выдаст сообщение с подтверждением права собственности на сайт, что будет говорить о включении ресурса в индекс данным В«поисковикомВ».
2. Яндекс.Вебмастер:
- Здесь форма добавления находится по адресу:В http://webmaster.yandex.ru/addurl.xml.
- Откроется форма, где необходимо прописать адрес главной страницы продвигаемого ресурса. Система обычно требует ввести капчу, после чего нужно нажать кнопка В«ДобавитьВ».
- Система поиска Яндекс проверяет ресурс, после чего выдает ответ, решение по вопросу индексации. Если Яндекс пишет, что сайт добавлен, значит, ресурс поставили в очередь на индексацию. Проблемы с сервером будут являться причиной ответа системы: В« Ваш хостинг не отвечаетВ».
Если В«поисковикВ» выдает сообщение ««указанный URL запрещен к индексацииВ», это говорит о наложенных на сайт санкциях. В этом случае потребуется срочно связаться со специалистами техподдержки Яндекса.
Помимо индексации в основных системах, не стоит забывать и о чуть менее известных В«поисковикахВ»:
- Рамблер ориентируется на индексацию ресурса в Яндексе, поэтому для добавления в его базу индекса достаточно пройти индексацию в основной поисковой системе.
- Индексацию в Mail.ru производят здесь:В http://go.mail.ru/addurl.
- Трафик русской поисковой системы Nigma.ru составляет около 3000000 в сутки. Подать заявку на индексацию в этой системе можно здесь:В http://www.nigma.ru/index_menu.php?menu_element=add_site.
Старый контент всегда нужно обновлять.
Платформа wordpress хорошо подходит дляВ персонального блоггинга, читай здесь, как стать настоящим профессионалом.В
Хочешь сделать красивую обложку для фейсбука, все подробности в нашей статье.В
Другие способы настройки индексации
Поисковые системы принимают решение об индексации сайта, независимо от желания владельца ресурса о индексации.
Поэтому термин В«настройкаВ» относительно процесса индексации звучит не совсем корректно.
Правильнее было бы сказать о формировании условий для принятия поисковой системой положительного решения об индексации ресурса.
К таким условиям можно отнести:
- Создание в социальных сетях сообществ, рассказывающих о ресурсе. Направление потока посетителей посредством выкладывания записей с интересной информацией с предложением перейти по ссылке для уточнения интересующих моментов, заказа, получения большей информации по обозначенному вопросу.
- Для повышения вероятности одобрения сайта и индексации его в Google полезно зарегистрировать аккаунт в данной системе и начать вести активную деятельность.
Необходимо понимать, что без индексации сайта поисковыми системами все последующие действия по продвижению будут бесполезными.
Поэтому данное действие необходимо произвести в первую очередь (для новых сайтов) и периодически проверять этот момент при включении свежей информации и добавлении целых страниц (для действующих ресурсов).
С уважением, Настя Чехова SEO специалист
ПОСМОТРИТЕ ВИДЕО(ЭТО ВАЖНО):
Оглавление:
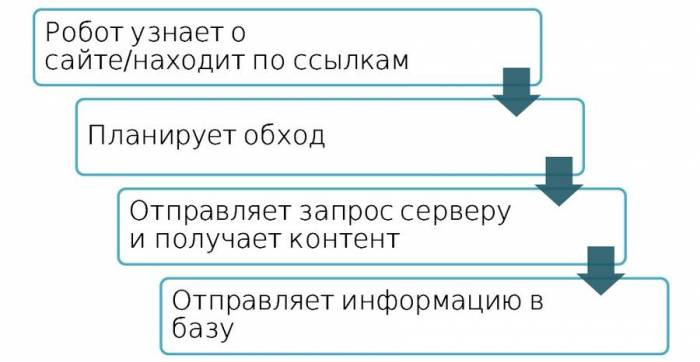
Как происходит процесс индексирования
Что такое индексирование? Это процесс получения роботом содержимого страниц вашего сайта и включение этого содержимого в результаты поиска. Если обратиться к цифрам, то в базе индексирующего робота содержится триллионы адресов страниц сайта. Ежедневно робот запрашивает миллиарды таких адресов.
Но этот весь большой процесс индексирования Интернета можно разделить на небольшие этапы:
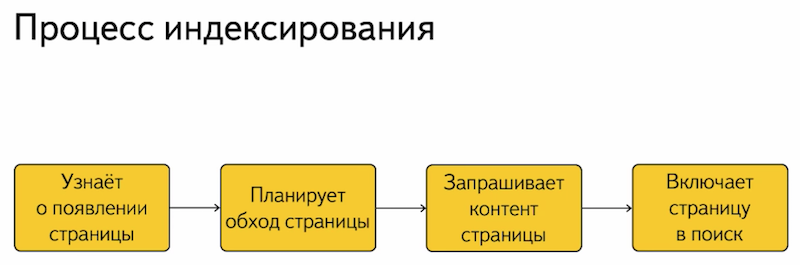
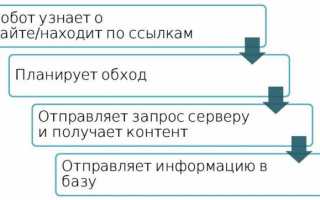
Во-первых, индексирующий робот должен узнать о появлении страницы вашего сайта. Например, проиндексировав другие страницы в Интернете, найдя ссылки, либо загрузив файл set nemp. О страничке мы узнали, после чего планируем обход этой страницы, отправляем данные к вашему серверу на запрос этой страницы сайта, получаем контент и включаем его в результаты поиска.
Этот весь процесс – это процесс обмена индексирующим роботом с вашим сайтом. Если запросы, которые посылает индексирующий робот, практически не меняются, а меняется только адрес страницы, то ответ вашего сервера на запрос страницы роботом зависит от многих факторов:
- от настроек вашей CMS;
- от настроек хостинг провайдера;
- от работы промежуточного провайдера.
Этот ответ как раз меняется. Прежде всего при запросе страницы робот от вашего сайта получает такой служебный ответ:

Это HTTP заголовки. В них содержится различная служебная информация, которая дает роботу понять передача какого контента сейчас будет происходить.
Мне хочется остановиться на первом заголовке – это HTTP-код ответа, который указывает индексирующему роботу на статус страницы, которую запросил робот.
Таких статусов HTTP-кодов несколько десятков:

Я расскажу о самых популярных. Наиболее распространенный код ответа – это HTTP-200. Страница доступна, ее можно индексировать, включать в результаты поиска, все отлично.
Противоположность этого статуса – это HTTP-404. Страница отсутствует на сайте, индексировать нечего, включать в поиск тоже нечего. При смене структуры сайтов и смене адресов внутренних страниц мы советуем настраивать 301 сервер на редирект. Как раз он укажет роботу на то, что старая страница переехала на новый адрес и необходимо включать в поисковую выдачу именно новый адрес.
Если контент страницы не менялся с последнего посещения страницы роботом, лучше всего возвращать код HTTP-304. Робот поймет, что обновлять в результатах поиска страницы не нужно и передача контента тоже не будет происходить.
При кратковременной доступности вашего сайта, например, при проведении каких-либо работ на сервере, лучше всего настраивать HTTP-503. Он укажет роботу на то, что сейчас сайт и сервер недоступны, нужно зайти немножко попозже. При кратковременной недоступности это позволит предотвратить исключение страниц из поисковой выдачи.
Помимо этих HTTP-кодов, статусов страниц, необходимо еще получить непосредственно контент самой страницы. Если для обычного посетителя страница выглядит следующим образом:
это картиночки, текст, навигация, все очень красиво, то для индексирующего робота любая страница – это просто набор исходного кода, HTML-кода:

Различные метатеги, текстовое содержимое, ссылки, скрипты, куча всякой информации. Робот собирает ее и включает в поисковую выдачу. Кажется, все просто, запросили страницу – получили статус, получили содержимое, включили в поиск.
Но недаром в службу поискового сервиса в Яндексе приходит более 500 писем от вебмастеров и владельцев сайтов о том, что возникли определенные проблемы как раз с ответом сервера.
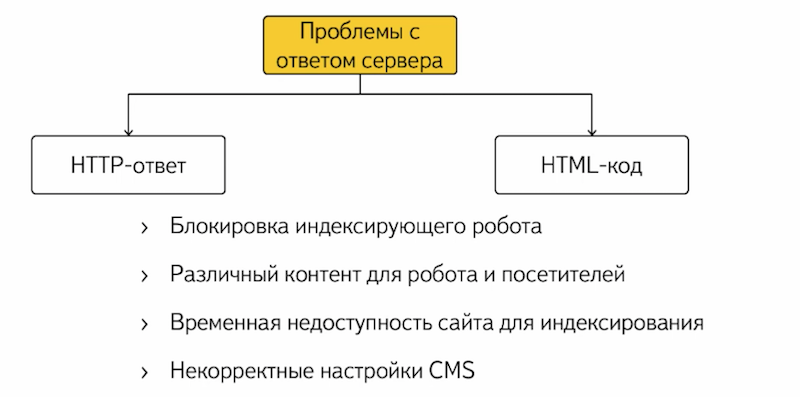
Все эти проблемы можно разделить на две части:
Это проблемы с HTTP-кодом ответа и проблемы с HTML-кодом, с непосредственным содержимым страниц. Причин возникновения этих проблем может быть огромное множество. Самая распространенная – это блокировка индексирующего робота хостинг-провайдером.
Например, вы запустили сайт, добавили новый раздел. Робот начинает посещать ваш сайт чаще, увеличивает нагрузку на сервер. Хостинг-провайдер видит это на своих мониторингах, блокирует индексирующего робота, и поэтому робот не может получить доступ к вашему сайту. Вы заходите на ваш ресурс – все отлично, все работает, странички красивенькие, все открывается, все супер, робот при этом проиндексировать сайт не может. При временной недоступности сайта, например, если забыли оплатить доменное имя, сайт отключен на несколько дней. Робот приходит на сайт, он недоступен, при таких условиях он может пропасть из поисковой выдачи буквально через некоторое время.
Некорректные настройки CMS, например, при обновлении или переходе на другую CMS, при обновлении дизайна, так же могут послужить причиной того, что страницы вашего сайта могут пропасть из выдачи при некорректных настройках. Например, наличие запрещающего метатега в исходном коде страниц сайта, некорректная настройка атрибута canonical. Проверяйте, что после всех изменений, которые вы вносите на сайт, страницы доступны для робота.
В этом вам поможет инструмент в Яндекс. Вебмастере по проверке ответа сервера:
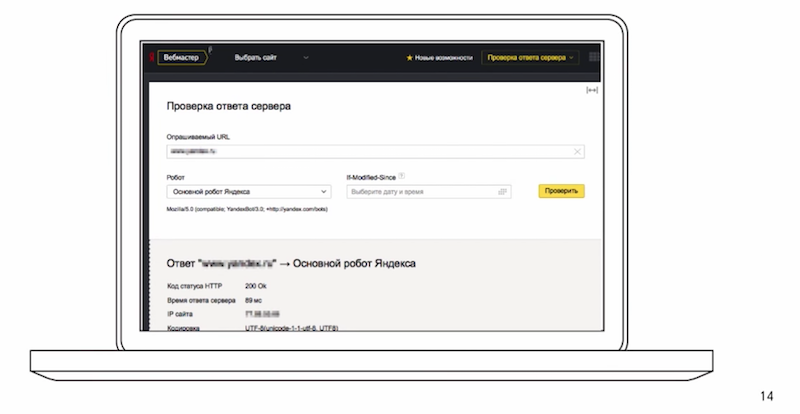
Можно посмотреть какие HTTP заголовки возвращает ваш сервер роботу, непосредственно содержимое страниц.
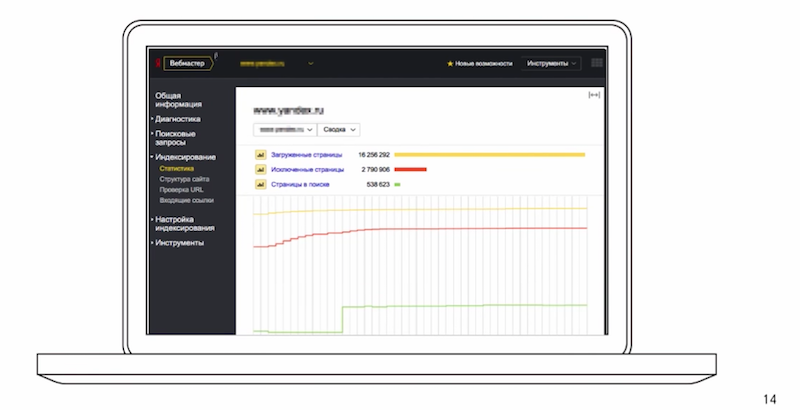
В разделе «индексирование» собрана статистика, где вы можете посмотреть какие страницы исключены, динамику изменения этих показателей, сделать различную сортировку и фильтрацию.
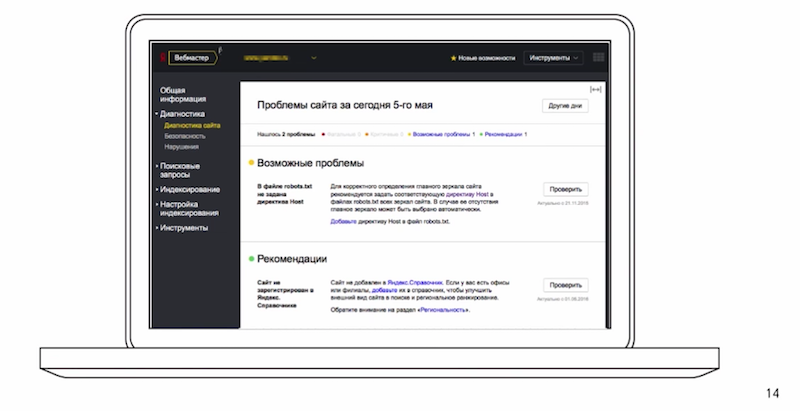
Так же, уже сегодня говорил об этом разделе, раздел «диагностика сайта». В случае, если ваш сайт стал недоступен для робота, вы получите соответствующее уведомление и рекомендации. Каким образом это можно исправить? Если таких проблем не возникло, сайт доступен, отвечает кодам-200, содержит корректный контент, то робот начинает в автоматическом режиме посещать все страницы, которые он узнает. Не всегда это приводит к нужным последствиям, поэтому деятельность робота можно определенным образом ограничить. Для этого существует файл robots.txt. О нем мы и поговорим в следующем разделе.
Настройка индексирования сайта в Яндексе: от теории к практике
Robots.txt
Сам по себе файлик robots.txt – это небольшой текстовый документ, лежит он в корневой папке сайта и содержит строгие правила для индексирующего робота, которые нужно выполнять при обходе сайта. Преимущества файла robots.txt заключаются в том, что для его использования не нужно особых и специальных знаний.
Достаточно открыть Блокнот, ввести определенные правила по формату, а затем просто сохранить файл на сервере. В течении суток робот начинает использовать эти правила.
Если взять пример файла robots.txt простенького, вот он, как раз на следующем слайде:

Директива User-Agent:” показывает для каких роботов предназначается правило, разрешающиезапрещающие директивы и вспомогательные директивы Sitemap и Host. Немножко теории, хочется перейти к практике.
Несколько месяцев назад мне захотелось купить шагометр, поэтому я обратился к Яндекс. Маркету за помощью с выбором. Перешел с главной страницы Яндекс на Яндекс. Маркет и попал на главную страницу сервиса.
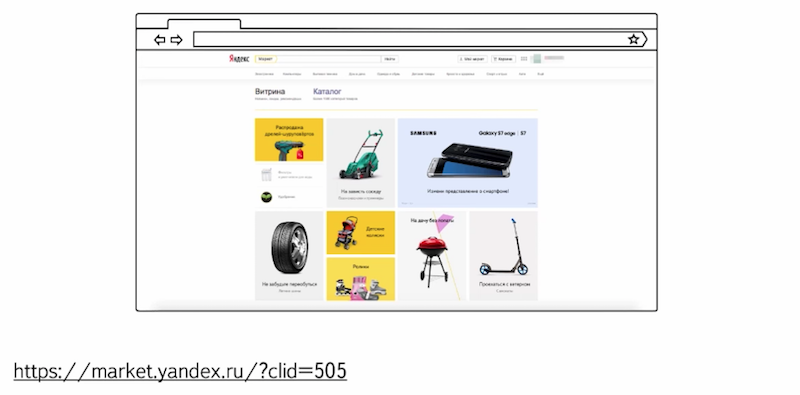
Внизу вы видите адрес страницы, на которую я перешел. К адресу самого сервиса еще добавился идентификатор меня, как пользователя на сайте.
Потом я перешел в раздел «каталог»
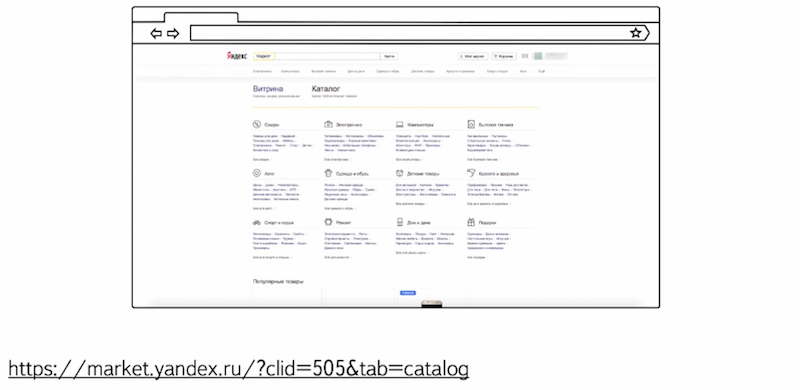
Выбрал нужный подраздел и настроил параметры сортировки, цену, фильтр, как сортировать, производителя.
Получил список товаров, и адрес страницы уже разросся.
Зашел на нужный товар, нажал на кнопочку «добавить в корзину» и продолжил оформление.
За время моего небольшого путешествия адреса страниц менялись определенным образом.

К ним добавлялись служебные параметры, которые идентифицировали меня, как пользователя, настраивали сортировку, указывали владельцу сайта откуда я перешел на ту или иную страницу сайта.
Такие страницы, служебные страницы, я думаю, что не очень будут интересны пользователям поисковой системы. Но если они будут доступны для индексирующего робота, в поиск они могут попасть, поскольку робот себя ведет, по сути, как пользователь.
Он переходит на одну страничку, видит ссылочку, на которую можно кликнуть, переходит на нее, загружает данные в базу робота свою и продолжает такой обход всего сайта. В эту же категорию таких адресов можно отнести и личные данные пользователей, например, такие, как информация о доставке, либо контактные данные пользователей.
Естественно, их лучше запрещать. Как раз для этого и поможет вам файл robots.txt. Вы можете сегодня вечером по окончанию Вебмастерской прийти на свой сайт, покликать, посмотреть какие страницы действительно доступны.
Для того, чтобы проверить robots.txt существует специальный инструмент в Вебмастере:
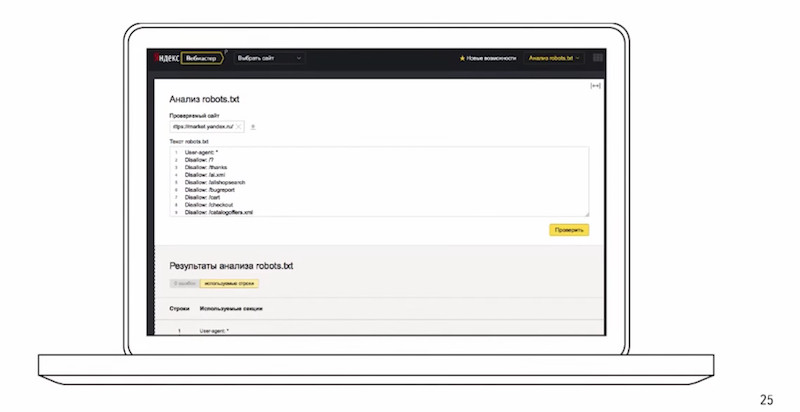
Можно загрузить, ввести адреса страниц, посмотреть доступны они для робота или нет.
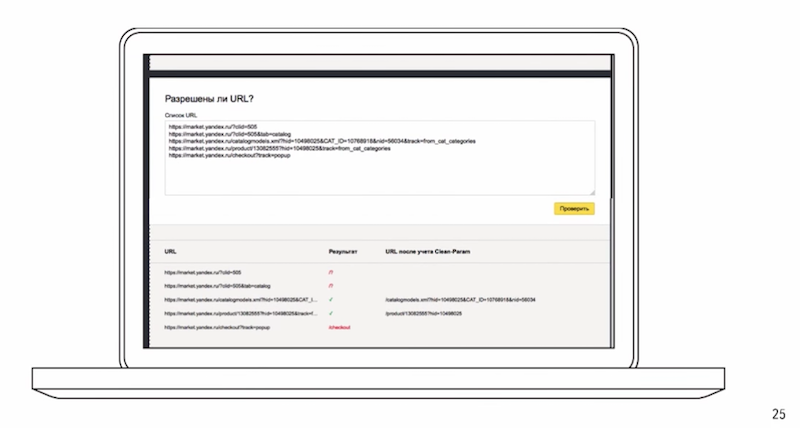
Внести какие-то изменения, посмотреть, как отреагирует робот на эти изменения.
Ошибки при работе с robots.txt
Помимо такого положительного влияния – закрытие служебных страниц, robots.txt при неправильном обращении может сыграть злую шутку.
Во-первых, самая распространенная проблема при использовании robots.txt – это закрытие действительно нужных страниц сайта, те, которые должны находиться в поиске и показываться по запросам. Прежде чем вы вносите изменения в robots.txt, обязательно проверьте не участвует ли страница, которую вы хотите закрыть, не показывается ли по запросам в поиске. Возможно страница с каким-то параметрами находится в выдаче и к ней приходят посетители из поиска. Поэтому обязательно проверьте перед использованием и внесением изменений в robots.txt.
Во-вторых, если на вашем сайте используются кириллические адреса, в robots.txt их указать не получится в прямом виде, их обязательно нужно кодировать. Поскольку robots.txt является международным стандартным, им следуют все индексирующие роботы, их обязательно нужно будет закодировать. Кириллицу в явном виде указать не получится.
Третья по популярности проблема – это различные правила для разных роботов разных поисковых систем. Для одного индексирующего робота закрыли все индексирующие страницы, для второго не закрыли совсем ничего. В результате этого у вас в одной поисковой системе все хорошо, в поиске нужная страница, а в другой поисковой системе может быть трэш, различные мусорные страницы, еще что-то. Обязательно следите, если вы устанавливаете запрет, его нужно делать для всех индексирующих роботов.
Четвертая по популярности проблема – это использование директивы Crawl-delay, когда в этом нет необходимости. Данная директива позволяет повлиять на чистоту запросов со стороны индексирующего робота. Это практический пример, маленький сайт, разместили его на небольшом хостинге, все прекрасно. Добавили большой каталог, робот пришел, увидел кучу новых страниц, начинает чаще обращаться на сайт, увеличивает нагрузку, скачивает это и сайт становится недоступным. Устанавливаем директиву Crawl-delay, робот видит это, снижает нагрузку, все отлично, сайт работает, все прекрасно индексируется, находится в выдаче. Спустя какое-то время сайт разрастается еще больше, переносится на новый хостинг, который готов справляться с этими запросами, с большим количеством запросов, а директиву Crawl-delay забывают убрать. В результате чего робот понимает, что на вашем сайте появилось очень много страниц, но не может их проиндексировать просто из-за установленной директивы. Если вы когда-либо использовали директиву Crawl-delay, проверьте, что сейчас ее нет и что ваш сервис готов справиться с нагрузкой от индексирующего робота.

Помимо описанной функциональности файл robots.txt позволяет еще решить две очень важные задачи – избавиться от дублей на сайте и указать адрес главного зеркала. Об этом как раз мы и поговорим в следующем разделе.
Подробнее: Использование файла robots.txt для SEO
Дубли

Под дублями мы понимаем несколько страниц одного и того же сайта, которые содержат абсолютно идентичный контент. Самый распространенный пример – это страницы со слешом и без слеша в конце адреса. Так же под дублем можно понимать один и тот же товар в различных категориях.
Например, роликовые коньки могут быть для девочек, для мальчиков, одна и та же модель может находиться в двух разделах одновременно. И, в-третьих, это страницы с незначащим параметром. Как в примере с Яндекс. Маркетом эта страничка «идентификатор сессии», такой параметр не меняет контент страницы в принципе.
Чтобы обнаружить дубли, посмотреть к каким страницам робот обращается, вы можете использовать Яндекс. Вебмастер.
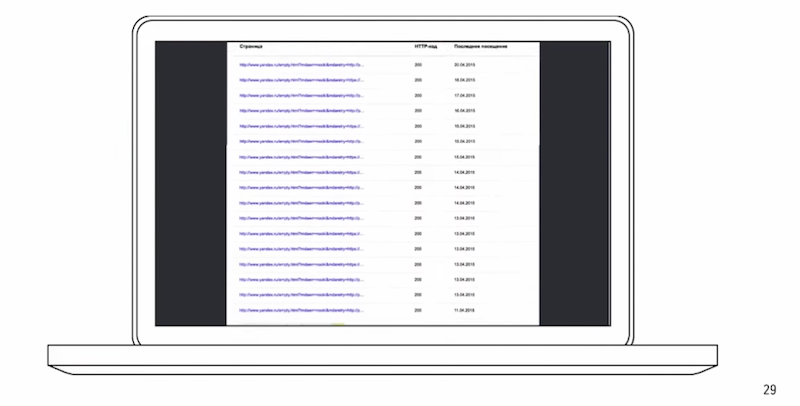
Помимо статистики есть еще и адреса страниц, которые робот загрузил. Вы видите код и последнее обращение.
Неприятности, к которым приводят дубли
Чем же плохи дубли?
Во-первых, робот начинает обращаться к абсолютно идентичным страницам сайта, что создает дополнительную нагрузку не только на ваш сервер, но и влияет на обход сайта в целом. Робот начинает уделять внимание дублирующим страницам, а не тем страницам, которые нужно индексировать и включать в поисковую выдачу.

Вторая проблема – это то, что дублирующие страницы, если они доступны для робота, могут попасть в результаты поиска и конкурировать с основными страницами по запросам, что, естественно, может негативно повлиять на нахождение сайта по тем или иным запросам.
Как можно бороться с дублями?
Во втором случае можно использовать 301 серверный редирект, например, для ситуаций со слешом на конце адреса и без слеша. Установили перенаправление – дублей нет.

И в-третьем, как я уже говорил, это файл robots.txt. Можно использовать как запрещающие директивы, так и директиву Clean-param для того, чтобы избавиться от незначащих параметров.
Зеркала сайта
Вторая задача, которую позволяет решить robots.txt – это указать роботу на адрес главного зеркала.

Зеркала – это группа сайтов, которые абсолютно идентичны, как дубли, только различные два сайта. Вебмастера обычно с зеркалами сталкиваются в двух случаях – когда хотят переехать на новый домен, либо, когда для пользователя нужно сделать несколько адресов сайта доступными.
Например, вы знаете, что пользователи, когда набирают ваш адрес, адрес вашего сайта в адресной строке, часто делают одну и ту же ошибку – опечатываются, не тот символ ставят или еще что-то. Можно приобрести дополнительный домен для того, чтобы пользователям показывать не заглушку от хостинг-провайдера, а показывать тот сайт, на который они действительно хотели перейти.
Остановимся на первом пункте, потому что именно с ним чаще всего и возникают проблемы в работе с зеркалами.
Переезд сайта на новый домен
Весь процесс переезда я советую осуществлять по следующей инструкции. Небольшая инструкция, которая позволит вам избежать различных проблем при переезде на новое доменное имя:
Во-первых, вам необходимо сделать сайты доступными для индексирующего робота и разместить на них абсолютно идентичный контент. Так же убедитесь, что о существовании сайтов роботу известно. Проще всего добавить их в Яндекс. Вебмастер и подтвердить на них права.
Во-вторых, с помощью директивы Host указывайте роботу на адрес главного зеркала – тот, который должен индексироваться и находиться в результатах поиска.
Далее идем в бету Яндекс. Вебмастера, используем инструмент «переезд сайта» и указываем роботу о своих внесенных изменениях.
Ждем склейки и переноса всех показателей со старого сайта на новый.

Ошибки при работе с зеркалами
Но, естественно, при работе с зеркалами возникают ошибки.
Прежде всего самая главная проблема – это отсутствие явных указаний для индексирующего робота на адрес главного зеркала, тот адрес, который должен находиться в поиске. Проверьте на ваших сайтах, что в robots.txt у них указана директива хоста, и она ведет именно на тот адрес, который вы хотите видеть в поиске.
Вторая по популярности проблема – это использование перенаправления для того, чтобы сменить главного зеркала в уже имеющейся группе зеркал. Что происходит? Старый адрес, поскольку осуществляет перенаправление, роботом не индексируется, исключается из поисковой выдачи. При этом новый сайт в поиск не попадает, поскольку является неглавным зеркалом. Вы теряете трафик, теряете посетителей, я думаю, что это никому не нужно.

И третья проблема – это недоступность одного из зеркал при переезде. Самый распространенный пример в этой ситуации, когда скопировали контент сайта на новый адрес, а старый адрес просто отключили, не оплатили доменное имя и он стал недоступен. Естественно такие сайты склеены не будут, они обязательно должны быть доступны для индексирующего робота.
Полезные ссылки в работе:
- Больше полезной информации вы найдете в сервисе Яндекс.Помощь.
- Все инструменты, о которых я говорил и даже больше – есть бета-версия Яндекс.Вебмастера.
Настройка индексирования сайта в Яндексе: от теории к практике
Ответы на вопросы
«Спасибо за доклад. Нужно ли в robots.txt закрывать индексацию CSS-файлов для робота или нет?».
На текущий момент мы не рекомендуем закрывать их. Да, CSS, JavaScript лучше оставить, потому что сейчас, мы работаем над тем, чтобы индексирующий робот начал распознавать и скрипты на вашем сайте, и стили, видеть, как посетитель из обычного браузера.
«Подскажите, а если url’ы адресов сайта будут одинаковые, у старого и у нового – это нормально?».
Да, ничего страшного. По сути, у вас просто обновление дизайна, добавление какого-то контента.
«На сайте есть категория и она состоит из нескольких страниц: слеш, page1, page2, до 10-ти, допустим. На всех страницах один текст категории, и он, получается, дублирующий. Будет ли этот текст являться дубликатом или нужно его как-то закрывать, новый индекс на вторых и далее страницах?».
Прежде всего, поскольку на первой странице пагинации, а на второй странице контент, в целом-то, отличаются, они дублями не будут. Но нужно рассчитывать, что вторая, третья и дальше страницы пагинации могут попасть в поиск и показывать по какому-либо релевантному запросу. Лучше в страницах пагинации я бы рекомендовал использовать атрибут canonical, в самом лучшем случае – на странице, на которой собраны все товары для того, чтобы робот не включал страницы пагинации в поиске. Люди очень часто используют canonical на первую страницу пагинации. Робот приходит на вторую страницу, видит товар, видит текст, страницы в поиск не включает и понимает за счет атрибута, что надо включать в поисковую выдачу именно первую страницу пагинации. Используйте canonical, а сам текст закрывать, думаю, что не нужно.
Источник (видео): Как настроить индексирование сайта — Александр Смирнов
Используемые источники:
- https://texterra.ru/blog/kak-priruchit-poiskovogo-bota-gayd-po-indeksirovaniyu-sayta.html
- https://livesurf.ru/zhurnal/5913-indeksaciya-sajtov-v-yandeks.html
- https://o-es.ru/blog/kak-nastroit-indeksirovanie-sajta/

 Где настройки браузера в компьютере
Где настройки браузера в компьютере Настройка Google XML Sitemaps или успех быстрой индексации вашего сайта
Настройка Google XML Sitemaps или успех быстрой индексации вашего сайта Плагин All in One SEO Pack. Правильная настройка
Плагин All in One SEO Pack. Правильная настройка Настройка плагина Yoast SEO wordpress новая инструкция
Настройка плагина Yoast SEO wordpress новая инструкция