Содержание
- 1 Что такое Robots.txt
- 2 Базовый Robots.txt для WordPress
- 3 Расширенный Robots.txt для WordPress
- 4 Заключение
- 5 Для чего нужен robots.txt
- 6 Где лежит файл robots в WordPress
- 7 Как создать правильный robots txt
- 8 Настройка команд
- 9 Рабочий пример инструкций для WordPress
- 10 Как проверить работу robots.txt
- 11 Плагин–генератор Virtual Robots.txt
- 12 Добавить с помощью Yoast SEO
- 13 Изменить модулем в All in One SEO
- 14 Правильная настройка для плагина WooCommerce
- 15 Итог
- 16 Правильный robots txt для WordPress.
- 17 Правильная настройка robots txt.
- 18 Разбор примера популярного роботса для ВП.
- 19 Что же закрывать в robots txt.
Одной из важнейших вещей при создании и оптимизации сайта для поисковых систем считают Robots.txt. Небольшой файлик, где прописаны правила индексирования для поисковых роботов.
Если файл будет настроен неправильно, то сайт может неправильно индексироваться и терять большие доли трафика. Грамотная настройка наоборот позволяет улучшить SEO, и вывести ресурс в топы.
Сегодня мы поговорим о настройке Robots.txt для WordPress. Я покажу вам правильный вариант, который сам использую для своих проектов.
Содержание
Что такое Robots.txt
Как я уже и сказал, robots.txt — текстовой файлик, где прописаны правила для поисковых систем. Стандартный robots.txt для WordPress выглядит следующим образом:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Именно в таком виде он создается плагином Yoast SEO. Некоторые считают, что этого хватит для правильной индексации. Я же считаю, что нужна более детальная проработка. А если речь идет о нестандартных проектах, то проработка нужна и подавно. Давайте разберемся в основных директивах:
| Директива | Значение | Пояснение |
| User-agent: | Yandex, Googlebot и т.д. | В этой директиве можно указать к какому конкретно роботу мы обращаемся. Обычно используются те значения, которые я указал. |
| Disallow: | Относительная ссылка | Директива запрета. Ссылки, указанные в этой директиве будут игнорироваться поисковыми системами. |
| Allow: | Относительная ссылка | Разрешающая директива. Ссылки, которые указаны с ней будут проиндексированы. |
| Sitemap: | Абсолютная ссылка | Здесь указывается ссылка на XML-карту сайта. Если в файле не указать эту директиву, то придется добавлять карту вручную (через Яндекс.Вебмастер или Search Console). |
| Crawl-delay: | Время в секундах (пример: 2.0 — 2 секунды) | Позволяет указать таймаут между посещениями поисковых роботов. Нужна в случае, если эти самые роботы создают дополнительную нагрузку на хостинг. |
| Clean-param: | Динамический параметр | Если на сайте есть параметры вида site.ru/statia?uid=32, где ?uid=32 — параметр, то с помощью этой директивы их можно скрыть. |
В принципе, ничего сложного. Дам дополнительные пояснения по директивам Clean-param (откройте вкладку).
Параметры, как правило, используются на динамических сайтах. Они могут передавать поисковым системам лишнюю информацию — создавать дубли. Чтобы избежать этого, мы должны указать в Robots.txt директиву Clean-param с указанием параметра и ссылки, к которой это параметр применяется.
В нашем примере site.ru/statia?uid=32 — site.ru/statia — ссылка, а все, что после знака вопроса — параметр. Здесь это uid=32. Он динамический, и это значит, что параметр uid может принимать другие значения.
Например, uid=33, uid=34…uid=123434. В теории их может быть сколько угодно, поэтому мы должны закрыть от индексации все параметры uid. Для этого директива должна принять такой вид:
 Как легко и пошагово установить WordPress на локальный компьютер
Как легко и пошагово установить WordPress на локальный компьютерClean-param: uid /statia # все параметры uid для statia будут закрыты
Более подробно о том, что такое Robots.txt можно узнать из Яндекс.Помощи. Или из этого видеоролика:
Базовый Robots.txt для WordPress
Совсем недавно я приобрел плагин Clearfy Pro для своих проектов. Там очень много разных функций, и одна из них — создание идеального Robots.txt. На самом деле насколько он идеален — я не знаю, вебмастера расходятся во мнениях.
Кто-то предпочитает делать более краткие версии роботса, указывая правила для всех поисковых систем сразу. Другие прописывают отдельные правила для каждого поисковика (в основном для Яндекса и Гугла).
Что из этого правильно — точно сказать не могу. Однако я предлагаю вам ознакомиться с базовой версией Robots.txt для WordPress от Clearfy Pro. Я немного подредактировал ее — указал директиву Sitemap. Удалил директиву Host.
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.php Disallow: /readme.html Disallow: /*? Disallow: /?s= Allow: /*.css Allow: /*.js Sitemap: https://site.ru/sitemap.xml
Не могу сказать, что это лучший вариант для блогов на ВП. Но во всяком случае, он лучше, чем то, что нам предлагает Yoast SEO по умолчанию.
Расширенный Robots.txt для WordPress
Теперь посмотрим на расширенную версию Robots.txt для WordPress. Наверняка вы знаете, что все сайты на WP имеют одинаковую структуру. Одинаковые названия папок, файлов и т.д. позволяют специалистам выявить наиболее приемлемый вариант роботса.
Читайте также: Самые лучшие SEO-оптимизированные шаблоны для WordPress
В этой статье я хочу представить вам свой вариант Robots.txt. Его я использую как для своих сайтов, так и для клиентских. Вы могли видеть такой вариант и на других сайтах, т.к. он обладает некоторой популярностью.
Итак, правильный Robots.txt для WordPress выглядит следующим образом:
 Самый лучший слайдер для WordPress: плагин Smart Slider 3 и его использование
Самый лучший слайдер для WordPress: плагин Smart Slider 3 и его использованиеUser-agent: * # Для всех поисковых систем, кроме Яндекса и Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Disallow: /tag/ # Закрываем метки Disallow: /readme.html # Закрываем бесполезный мануал по установке WordPress (лежит в корне) Disallow: *?replytocom Allow: */uploads User-agent: GoogleBot # Для Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Disallow: /tag/ # Закрываем метки Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php User-agent: Yandex # Для Яндекса Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: /tag/ # Закрываем метки Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign Clean-Param: openstat Sitemap: https://site.com/sitemap_index.xml # Карта сайта, меняем site.com на нужный адрес.
Важно:Ранее в Robots.txt использовалась директива Host. Она указывала главное зеркало сайта. Теперь это делается при помощи редиректа. Подробнее об этом можно почитать в блоге Яндекса.
Комментарии (текст после #) можно удалить. Указываю Sitemap с https протоколом, т.к. большинство сайтов сейчас используют защищенное соединение. Если у вас нет SSL, то измените протокол на http.
Читайте также: Как правильно настроить WordPress
Обратите внимание на то, что я закрываю метки (теги). Делаю это потому, что они создают большое количество дублей. Это плохо сказывается на SEO, но если вы хотите открыть метки, тогда уберите строчку disallow: /tag/ из файла.
Заключение
В общем-то, вот так выглядит правильный Robots.txt для WordPress. Смело копируйте данные в файл и пользуйтесь. Отмечу, что этот вариант подходит только для стандартных информационных сайтов.
В других ситуациях может потребоваться индивидуальная проработка. На этом все. Спасибо за внимание. Буду благодарен, если вы включите уведомления через колокольчик и подпишитесь на почтовую рассылку. Тут будет круто :).
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Содержание
Для чего нужен robots.txt
Robots.txt создан для регулирования поведения поисковых роботов на сайтах, а именно куда им заходить можно и брать в поиск, а куда нельзя. Лет 10 назад сила данного файла была велика, по его правилам работали все поисковые системы, но сейчас он скорее как рекомендация, чем правило.
 11 советов по настройке файла wp-config.php
11 советов по настройке файла wp-config.phpНо пока не отменили, вебмастера должны делать его и настраивать правильно исходя из структуры и иерархии сайтов. Отдельная тема это WordPress, потому что CMS содержит множество элементов, которые не нужно сканировать и отдавать в индекс. Разберемся как правильно составить robots.txt
Где лежит файл robots в WordPress
На любом из ресурсов robots.txt должен лежать в корневой папке. В случае с вордпресс, там где находится папка wp-admin и ей подобные.
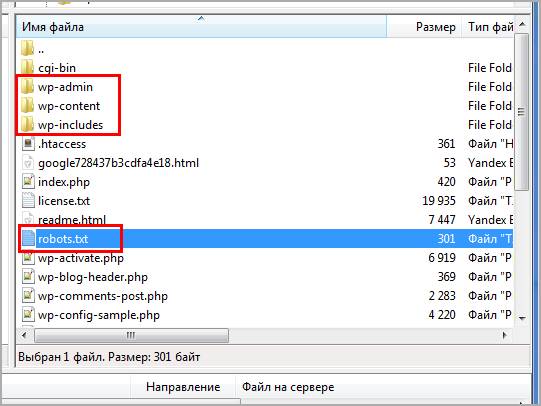
Если не создавался и не загружался администратором сайта, то по умолчанию на сервере не найти. Стандартная сборка WordPress не предусматривает наличие такого объекта.
Как создать правильный robots txt
Создать правильный robots txt задача не трудная, сложнее прописать в нем правильные директивы. Сначала создадим документ, открываем программу блокнот и нажимаем сохранить как.
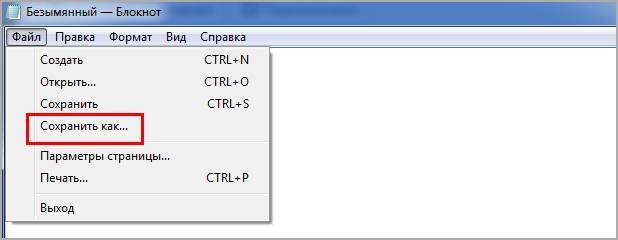
В следующем окне задаем название robots, оставляем расширение txt, кодировку ANSI и нажимаем сохранить. Объект появится в папке куда произошло сохранение. Пока документ пустой и ничего не содержит в себе, давайте разберемся какие именно директивы он может поддерживать.
При желании можете сразу скачать его на сервер в корень через программу FileZilla.
Настройка команд
Выделю четыре основные команды:
- User-agent: показывает правила для разных поисковых роботов, либо для всех, либо для отдельных
- Disalow: запрещает доступ
- Allow: разрешаем доступ
- Sitemap: адрес до XML карты
Устаревшие и ненужные конфигурации:
- Host: указывает главное зеркало, стало не нужным, потому что поиск сам определит правильный вариант
- Crawl-delay: ограничивает время на пребывание робота на странице, сейчас сервера мощные и беспокоится о производительности не нужно
- Clean-param: ограничивает загрузку дублирующегося контента, прописать можно, но толку не будет, поисковик проиндексирует все, что есть на сайте и возьмет по–максимому страниц
Рабочий пример инструкций для WordPress
Дело в том что поисковой робот не любит запрещающие директивы, и все равно возьмет в оборот, что ему нужно. Запрет на индексацию должен быть объектов, которые 100% не должны быть в поиске и в базе Яндекса и Гугла. Данный рабочий пример кода помещаем в robots txt.
User-agent: * Disallow: /wp- Disallow: /tag/ Disallow: */trackback Disallow: */page Disallow: /author/* Disallow: /template.html Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: *.js Allow: *.css Allow: *.png Allow: *.gif Allow: *.jpg Sitemap: https://ваш домен/sitemap.xmlРазберемся с текстом и посмотрим что именно мы разрешили, а что запретили:
- User-agent, поставили знак *, тем самым сообщив что все поисковые машины должны подчиняться правилам
- Блок с Disallow запрещает к индексу все технические страницы и дубли. обратите внимание что я заблокировал папки начинающиеся на wp-
- Блок Allow разрешает сканировать скрипты, картинки и css файлы, это необходимо для правильного представления проекта в поиске иначе вы получите портянку без оформления
- Sitemap: показывает путь до XML карты сайта, обязательно нужно ее сделать, а так же заменить надпись»ваш домен»
Остальные директивы рекомендую не вносить, после сохранения и внесения правок, загружаем стандартный robots txt в корень WordPress. Для проверки наличия открываем такой адрес https://your-domain/robots.txt, заменяем домен на свой, должно отобразится так.
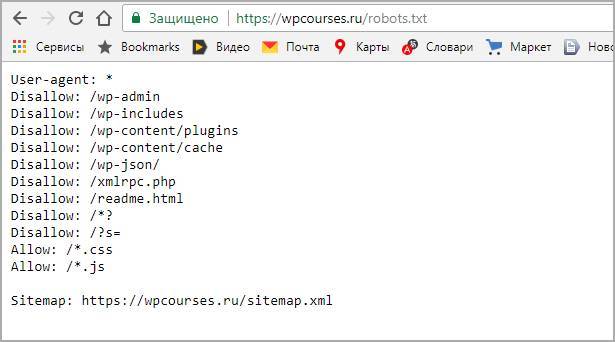
Как проверить работу robots.txt
Стандартный способ проверить через сервис yandex webmaster. Для лучшего анализа нужно зарегистрировать и установить на сайт сервис. Вверху видим загрузившийся robots, нажимаем проверить.
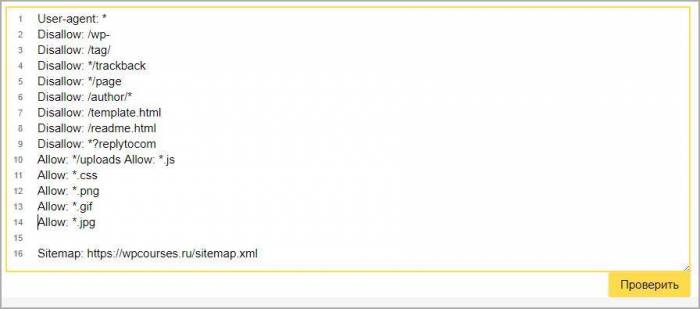
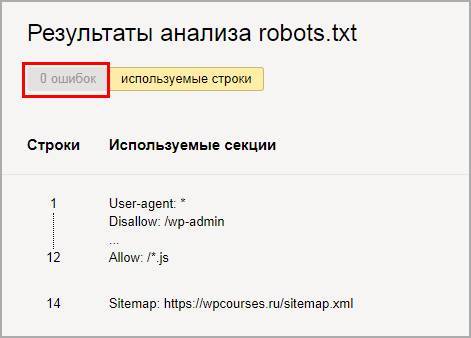
Ниже появится блок с ошибками, если их нет то переходим к следующему шагу, если неверно отображается команда, то исправляем и снова проверяем.
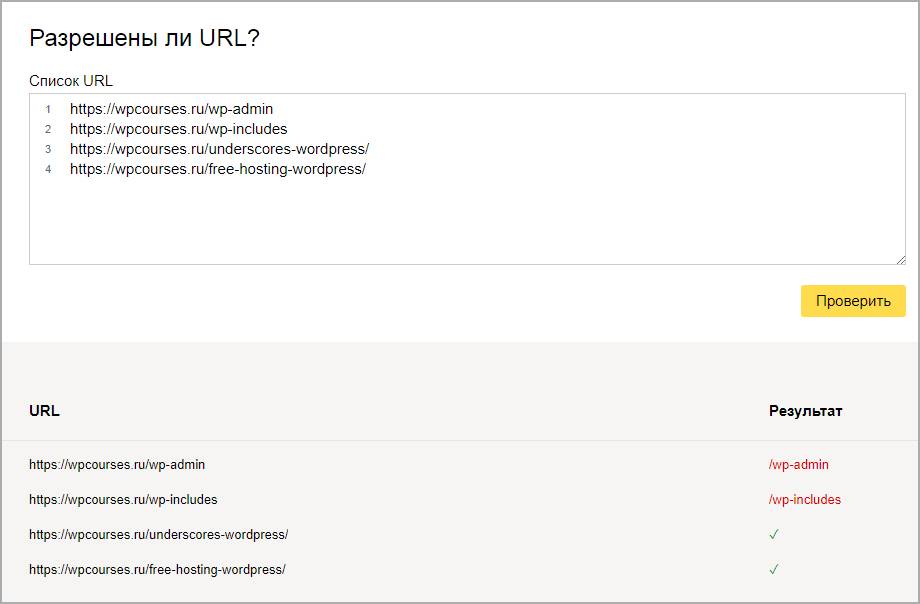
Проверим правильно ли Яндекс обрабатывает команды, спускаемся чуть ниже, введем два запрещенных и разрешенных адреса, не забываем нажать проверить. На снимке видим что инструкция сработала, красным помечено что вход запрещен, а зеленой галочкой, что индексирование записей разрешена.
Проверили, все срабатывает, перейдем к следующему способу это настройка robots с помощью плагинов. Если процесс не понятен, то смотрите наше видео.
Плагин–генератор Virtual Robots.txt
Если не хочется связываться с FTP подключением, то приходит на помощь один отличный WordPress плагин–генератор называется Virtual Robots.txt. Устанавливаем стандартно из админки вордпресс поиском или загрузкой архива, выглядит так.
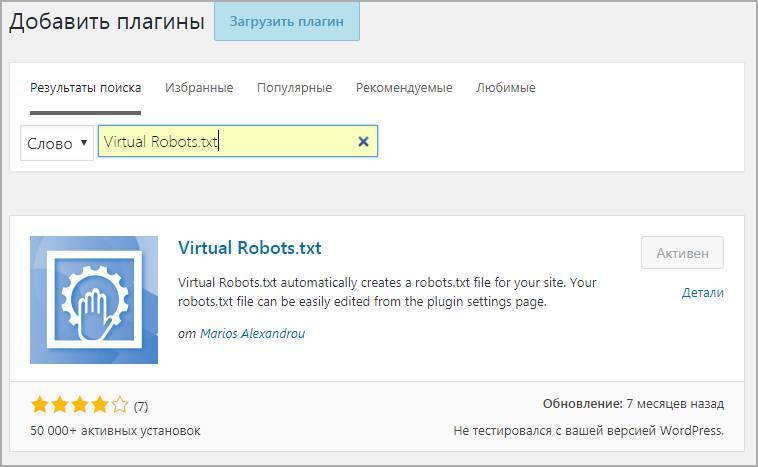
Переходим в админку Настройки > Virtual Robots.txt, видим знакомую конфигурацию, но нам нужно ее заменить, на нашу из статьи. Копируем и вставляем, не забываем сохранять.
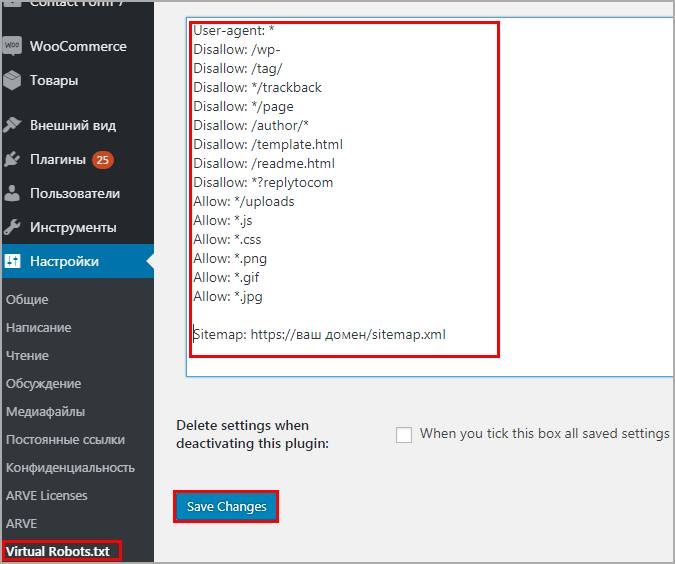
Роботс автоматически создастся и станет доступен по тому же адресу. При желании проверить есть он в файлах WordPress – ничего не увидим, потому что документ виртуальный и редактировать можно только из плагина, но Yandex и Google он будет виден.
Добавить с помощью Yoast SEO
Знаменитый плагин Yoast SEO предоставляет возможность добавить и изменить robots.txt из панели WordPress. Причем созданный файл появляется на сервере (а не виртуально) и находится в корне сайта, то есть после удаления или деактивации роботс остается. Переходим в Инструменты > Редактор.
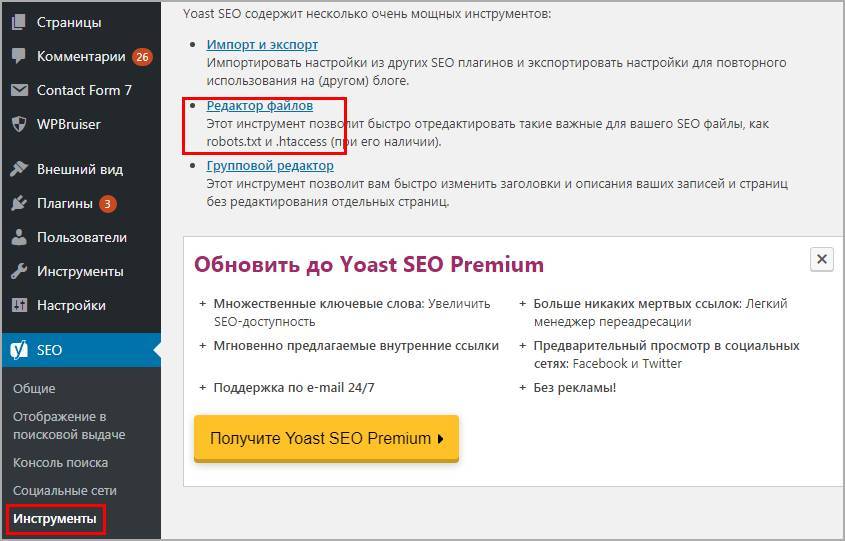
Если robots есть, то отобразится на странице, если нет есть кнопка «создать», нажимаем на нее.

Выйдет текстовая область, записываем, имеющийся текст из универсальной конфигурации и сохраняем. Можно проверить по FTP соединению документ появится.
Изменить модулем в All in One SEO
Старый плагин All in One SEO умеет изменять robots txt, чтобы активировать возможность переходим в раздел модули и находим одноименный пункт, нажимаем Activate.
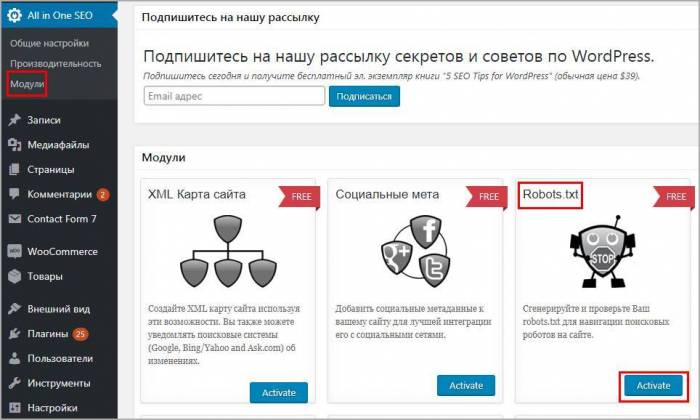
В меню All in One SEO появится новый раздел, заходим, видим функционал конструктора.
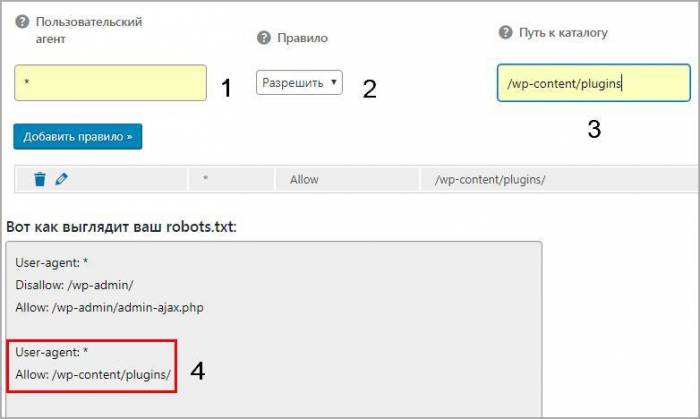
- Записываем имя агента, в нашем случае * или оставляем пустым
- Разрешаем или запрещаем индексацию
- Директория или страница куда не нужно идти
- Результат
Модуль не удобный, создать по такому принципу валидный и корректный robots.txt трудно. Лучше используйте другие инструменты.
Правильная настройка для плагина WooCommerce
Чтобы сделать правильную настройку для плагина интернет магазина на WordPress WooCommerce, добавьте эти строки к остальным:
Disallow: /cart/ Disallow: /checkout/ Disallow: /*add-to-cart=* Делаем аналогичные действия и загружаем на сервер через FTP или плагином.
Итог
Подведем итог что нужно сделать чтобы на сайте WordPress был корректный файл для поисковиков:
- Создаем вручную или с помощью плагина файл
- Записываем в него инструкции из статьи
- Загружаем на сервер
- Проверяем в валидаторе Yandex
- Не пользуйтесь генераторами robots txt в интернете, пошевелите немного руками
Совершенствуйте свои блоги на WordPress, продвигайтесь и правильно настраивайте все параметры, а мы в этом поможем, успехов!
Пожалуйста, оцените материал:
Правильный robots txt для WordPress.

Приветствую, дорогие вебмастера! С помощью этой статьи, я хочу показать вам как правильно настроить файл robots.txt для конкретного сайта. Но, чтобы научиться его составлять, вам необходимо вдумчиво прочитать эту статью (возможно, не один раз). Только поняв, что вы будете делать, вы сможете настраивать этот файл для любого сайта. Будь то интернет-магазин, корпоративный сайт или блог, не важно.
Для тех, кто ищет готовый вариант (универсальный) для всех сайтов, я вас разочарую… Такого не существует! На каждом сайте есть свои собственные разделы, папки и файлы, о которых невозможно предугадать заранее. Так что, лучше научиться один раз и не мучить каждый раз поисковик.
Составлять правильный файл robots txt мы будем сразу и для Яндекс’а и для Google одновременно. Иначе, смысла особого вообще не вижу. Я считаю, продвигаться нужно сразу в обоих и глупо делать упор только на один. Алгоритмы меняются постоянно и то, что работало сегодня во благо, завтра может сработать против.
Псевдо – правильный файл robots
Итак, для начала давайте разберемся что нужно закрывать в этом самом файле, а что уже давно кануло в лету. Все примеры правильного роботса, которые вы сможете найти в интернете (или уже нашли), написаны зачастую для конкретного сайта и к вашему не имеет вообще никакого отношения.
Обычно, в файле роботс советуют закрывать страницу входа в админку wp-login.php, саму страницу админки wp-admin, да и вообще всю директорию wp. Так же закрывают стили и скрипты js и css, и конечно же не нужные для индексирования страницы и всё в этом духе…
Но возникает вопрос, а нужно ли? Ведь большинство директорий, которые нужно было закрывать в роботс.тхт раньше, теперь закрываются более разумным методом – тегом robots. Почему более разумный спросите вы? На этот вопрос поможет ответить представитель Google Джон Мюллер в этом видео (включите русские титры, видео начинается с нужного места):
Немного поясню. Джон предупредил, что если в robots txt закрыть какую-то страницу или директорию, но при этом на неё вдруг будет проставлена ссылка в интернете, то эта страница или директория будет проиндексирована не зависимо от правила файла роботс.
С каждым годом, файл robots txt становиться всё бесполезнее и бессмысленнее. И этот ответ, тому подтверждение. Закрытие в этом файле вас уже можно сказать не спасёт, ссылка может появиться тысячами способов как автоматических, так и ручных. Поэтому Мюллер рекомендует закрывать не нужные страницы не файлом роботс, а тегом robots. Что собственно и я советую вам научиться делать.
Бессмысленность файла роботс.
Проанализируйте сами, большинство директив в файле уже упразднили к 2019 году:
- Crawl-delay (таймаут для роботов) перестали учитывать.
- Host (главное зеркало) тоже упразднили.
- Закрывать js и css Гугл не рекомендует, вебмастер ругается.
- Директива wp- и другие технические страницы закрываются тегом.
- Собственно, всё. Закрывать больше нечего.
А судя по тому, что как минимум, поисковик Google может проиндексировать закрытые страницы в файле роботс (не удивлюсь что и Яндекс тоже), то смысла закрывать не нужные страницы таким образом уже нет.
Единственное, что осталось для файла robots, так это пользовательские папки и директории, на которые точно никто не будет ссылаться и нет возможности проставить тег robots. К ним относятся собственные папки и пользовательские файлы у которых нет собственных страниц (например файлы для скачивания).
Что касается get параметров, в Яндекс’е есть специальная директива Clean-param, но используют её единицы. В Google же вообще не упоминается об этой директиве, похоже поэтому она и не обрела популярности в глазах вебмастеров. Поэтому, если вы всё же решили закрыть страницы с get параметрами, то закрывайте обычным синтаксисом.
Синтаксис файла для поисковиков.
Ниже представлена официальная документация для наших двух поисковиков. В принципе, этого будет достаточно, потому что остальным поисковикам приходиться ровняться на этих двух гигантов.
- Синтаксис файла robots.txt Яндекс.
- Синтаксис файла robots.txt Google.
Но я считаю, это бессмысленная затея, закрывать генерируемые страницы с get параметрами. Я никогда не закрываю такие страницы и проблем не возникало. Так что, решайте сами, этот пункт абсолютно не критичен.
Правильная настройка robots txt.
Простое удаление портянки из файла проблему не решит конечно же. Перед этим, нужно настроить закрытие не нужных страниц тегом robots, а уже потом удалять всё ненужное из файла. В идеале, у вас должен получиться вот такой роботс /robots.txt. То есть, закрыты только пользовательские директории и файлы, которые не должны быть в индексе и на которые никто не будет ссылаться в принципе. Директиву Host можете оставить, а можете и удалить. Поисковики её уже не учитывают, поэтому не парьтесь. Я оставил, мне она не мешает.
Закрывать ли wp-admin, wp-login и т.д.?
Закрывать эти директории уже нет необходимости и вот почему. Все технические страницы WordPress перенаправляет для не авторизованных пользователей на страницу входа wp-login.php. А если открыть код этой страницы CTRL+U и проверить его, вы увидите тег проставленный ВП автоматически:
То есть, движок уже закрыл эту страницу от индексации. И все остальные страницы тоже, так как не авторизованный пользователь на них не сможет попасть, в том числе и краулер поисковиков. Так что, директории wp-… можно смело удалять из файла robots txt. Идем дальше.
Закрывать ли от индексации js и css?
Как вы уже наверное знаете, поисковики очень много внимания уделяют мобильным (адаптивным) версиям сайта. И чтобы определить на сколько мобильна страница, краулеру необходимо проиндексировать файлы стилей и скриптов, чтобы понять это. Так вот, если вы будете закрывать стили css и скрипты js от индексации, большая вероятность что краулер посчитает ваш сайт убогим не адаптивным. Отсюда понижение выдачи, потеря посещаемости и все вытекающие.
Вот так должны воспринимать ваш сайт поисковики:
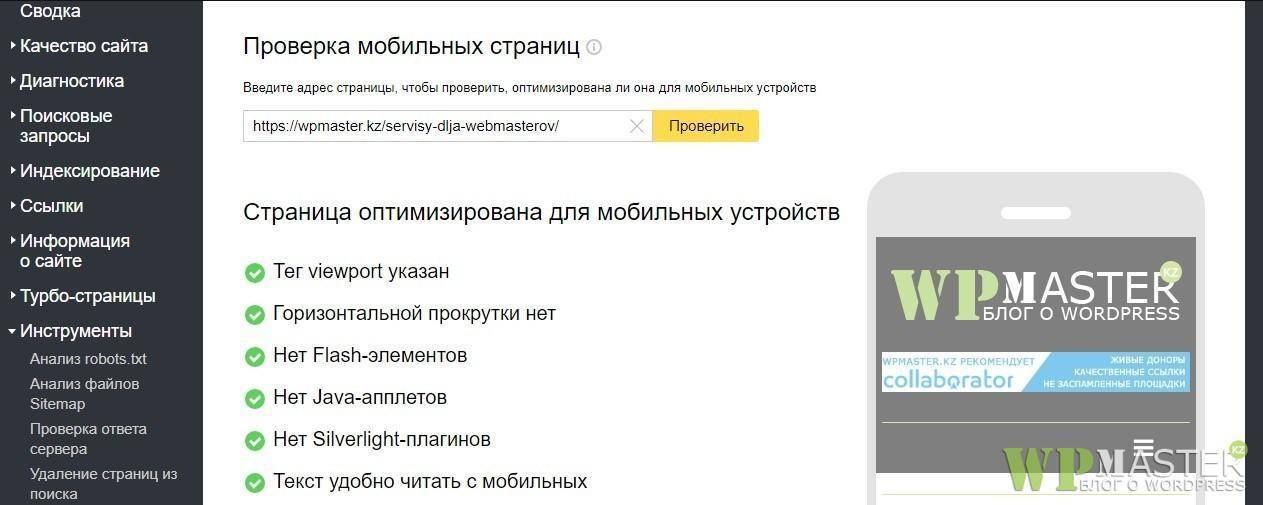
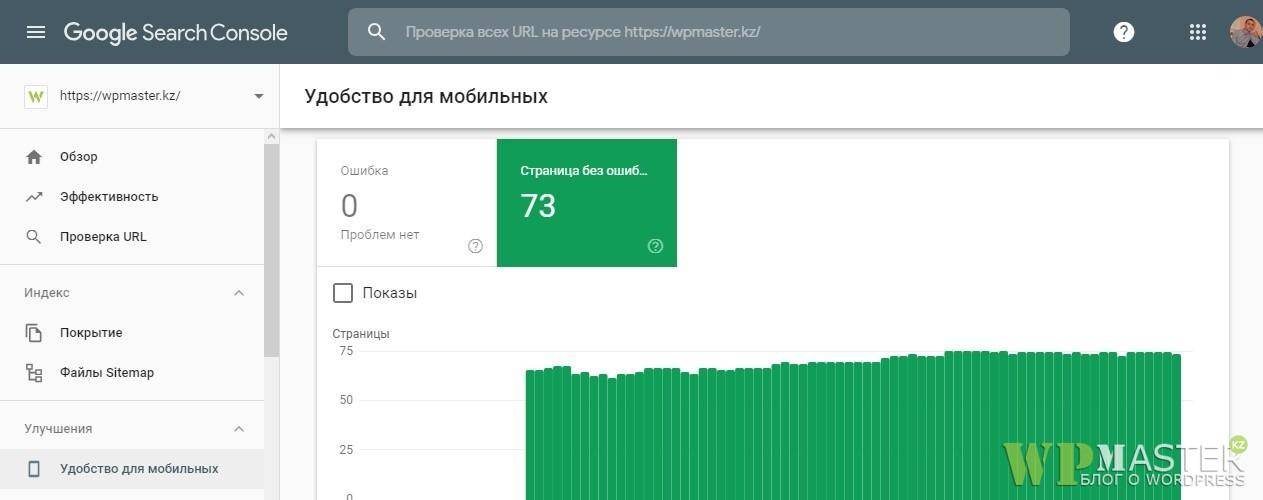
Конечно же, не стоит забывать о самой мобильности. Если сайт не адаптирован, открытие или закрытие тут явно не поможет избавиться от ошибок в вебмастерах. Исходя из выше описанного, закрытие стилей и скриптов в файле robots txt не желательное занятие. Удаляйте эти директивы и забудьте о них. Едем дальше.
Все эти технические страницы закрываются с помощью тега роботс. Отлично с этим справляется плагин Yoast SEO, рекомендую ознакомиться с обзором. В нем можно будет закрыть все не нужные архивы и метки в автоматическом режиме.
Что касается embed, pingback и подобных приблуд, с этим отлично справляются плагины Clearfy Webcraftic или Wpshop. Там вы сможете отключить не нужные директории сайта программно и закрывать их дополнительно ещё где либо не потребуется.
И наконец, что касается страниц пагинации page. Закрывать от индексации их даже тегом роботс не рекомендуется. Для таких страниц отлично подходит тег rel=»canonical», подробнее про него я писал ранее.
Разбор примера популярного роботса для ВП.
Вижу что многим читателям трудно воспринять теорию без практики, поэтому дополняю статью конкретным примером. Возьмём популярный вариант robots и разберём его по полочкам. Итак, вот он сам файл:
User-agent: * Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: */comments Disallow: /category/*/* Disallow: /trackback Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /feed/ Disallow: /*?* Disallow: /?s= User-agent: Yandex Disallow: /wp-login.php Disallow: /wp-register.php Disallow: /feed/ Disallow: /cgi-bin Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /trackback Disallow: */comments Disallow: /category/*/* Disallow: */trackback Disallow: */*/trackback Disallow: */*/feed/*/ Disallow: */feed Disallow: /*?* Disallow: /?s= Host: https://kakoytosite.ru Sitemap: https://kakoytosite.ru/sitemap.xml
Что мы видим? Первое что бросается в глаза, это дублирование условий для всех роботов user-agent: * и отдельно зачем-то для Яндекса user-agent: Yandex. Хочется сразу же спросить у автора – Вы действительно думаете что робот Яндекса тупой и не поймёт общие правила со звёздочкой? (это конечно же риторический вопрос).
Ну что ж, а теперь по порядку:
Disallow: /wp-login.php Disallow: /wp-register.php
Если вы читаете эту статью не из прошлого, то на борту у вас минимум должна быть версия WordPress 5.x.x не меньше. Так вот, страницы входа wp-login.php и wp-register.php по умолчанию наделены специальным тегом robots – nofollow. То есть, ВордПресс уже сам закрыл эти страницы от индексации и вам не нужно их больше нигде закрывать.
Disallow: /cgi-bin
Директория сервера это классика, только не понятно откуда она взялась. Эта директория изначально отдает 403 ошибку сервиса при переходе, поэтому она никак не может быть проиндексирована поисковиками. Стало быть, этот пункт из файла можно так же смело удалить.
Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes
Первые две директории wp-admin и wp-includes являются техническими. То есть, к ним нет доступа не авторизованным пользователям. В том числе и пауку (краулеру) не удастся попасть на эти страницы. Он будет автоматически перенаправлен на страницу входа wp-login.php которая уже закрыта тегом роботс от индексации.
Директории /wp-content/… отвечают за файлы ваших тем и плагинов, в том числе и за файлы js и css. Если закрывать эти файлы от индексации, то Google не сможет прочитать их и в вебмастере вы увидите ошибки, что сайт не адаптирован. Хотя он может быть полностью мобильным.
Disallow: */comments Disallow: /category/*/*
Скорее всего, это пользовательские директивы, которые были прописаны под конкретный сайт (как я и говорил в начале) и никаким боком к вашему не относятся. Но все просто копируют готовый и даже не думают, что они делают.
Disallow: /trackback Disallow: */trackback Disallow: */*/trackback
Это одна из приблуд движка WordPress. С помощью неё движок посылает уведомления на сайты, ссылки на которые у вас будут в статьях. Отключается это штатными средствами. В админке перейдите по пути Настройки > Обсуждение и уберите галочки на первых двух (верхних) пунктах.
Disallow: */*/feed/*/ Disallow: */feed Disallow: /feed/
Вообще не понимаю, зачем закрывать фиды от индексации? Поисковик фиды не индексирует и не выводит в выдаче. Вы хоть раз видели в поиске страницу фидов? Это один из бесполезных сео-маразмов. Удаляйте эти бессмысленные правила.
Disallow: /*?* Disallow: /?s=
Эти директории отвечают за страницы с get параметрами и за страницу поиска по сайту. Здесь уже решать вам, нужны ли они в индексе или нет. Я никогда их не закрываю и бед не знаю.
Что же закрывать в robots txt.
Исходя из выше написанного, остается закрывать только пользовательские папки и файлы, которые не относятся на прямую к самому сайту WordPress. То есть, ни папки темы, ни плагинов, а собственные, со сторонними файлами (например для скачивания и т.д.).
Закрывать картинки от индексирования – считаю маразмом. Это относиться к тому случаю, когда вы начитавшись, что не уникальные картинки портят репутацию, решаете их закрыть. Это бред собачий, но это личное ИМХО.
А вот различные рекламные баннеры и файлы для скачивания, можно поместить в отдельную пользовательскую папку (или в несколько) и закрыть эту папку от индексации в файле роботс. Собственно так я и поступил с папкой files в моём роботсе.
Заключение.
Как видите, файл robots txt потерял свою актуальность к 2019 году (по крайней мере в мире WordPress). Закрывать практически нечего, поэтому данный файл обречен пустовать и мозолить всем вебмастерам глаз. Надеюсь я был убедителен, если есть что сказать, прошу в комментарии. На этом блоге свобода слова, так что высказывайтесь на здоровье. На этом у меня всё, увидимся на страницах wpmaster.kz!
Бонус для читателей WPMaster.kz. Предлагаю познакомиться с новым разделом на блоге — Промокоды. Только самые лучшие и нужные промокоды для покупок плагинов, тем, обучения, сервисов и т.д.
Используемые источники:
- https://awayne.biz/pravilnyy-robots-txt-dlya-wordpress/
- https://wpcourses.ru/robots-txt-wordpress/
- https://wpmaster.kz/pravilnyy-robots-txt/

 Как создать базовую контактную форму с помощью плагина WPForms
Как создать базовую контактную форму с помощью плагина WPForms Почему вы не должны использовать настройки постоянных ссылок по умолчанию
Почему вы не должны использовать настройки постоянных ссылок по умолчанию Как настроить шаблон WordPress – встроенные инструменты кастомизации
Как настроить шаблон WordPress – встроенные инструменты кастомизации Перенос WordPress-сайта с сохранением настроек и URL’ов на новый сервер
Перенос WordPress-сайта с сохранением настроек и URL’ов на новый сервер