Содержание
- 1 Как влияет robots.txt на индексацию сайта
- 2 Директивы robots.txt
- 3 Закрывающий robots.txt
- 4 Правильная настройка robots.txt
- 5 Пример robots.txt
- 6 Как добавить и где находится robots.txt
- 7 Как проверить robots.txt
- 8 Типичные ошибки в robots.txt
- 9 P.S.
- 10 P.S.2
- 11 Что такое robots.txt и для чего он нужен
- 12 Как создать файл robots.txt на своем сайте?
- 13 Правильная настройка robots.txt для сайта
- 14 Запрет индексации в файле robots.txt — Disallow
- 15 Разрешить индексацию robots.txt — Allow
- 16 Главное зеркало сайта в robots.txt — Host
- 17 Карта сайта в robots.txt — Sitemap.xml
- 18 Директива Clean-param в robots.txt
- 19 Директива Crawl-delay в robots.txt
- 20 Комментарии в robots.txt
- 21 Как проверить robots.txt?
- 22 Robots.txt в Яндекс и Google
- 23 Заключение: советы Вебмастерам
- 24 Что такое Robots.txt
- 25 Базовый Robots.txt для WordPress
- 26 Расширенный Robots.txt для WordPress
- 27 Заключение
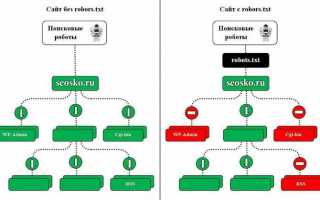
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Подробнее об исключениях:Исключения ЯндексаСтандарт исключений для роботов (Википедия)
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
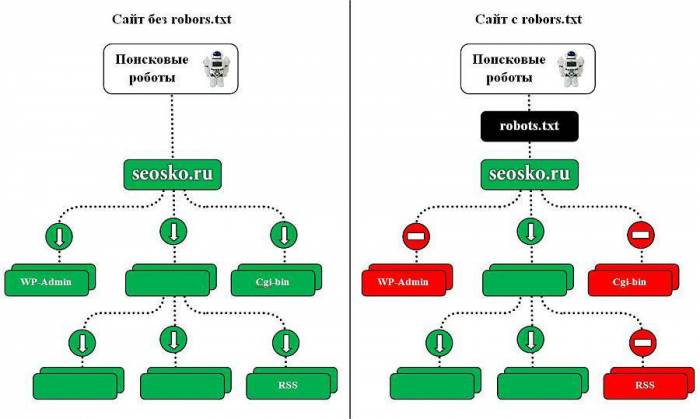
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:User-agent: *
 Подробная инструкция как установить робота на Форекс
Подробная инструкция как установить робота на ФорексДля конкретного бота:User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Но здесь не все так просто.
Во-первых, нужно знать дополнительные операторы и понимать, как они используются — это *, $ и #.
Примеры использования:
Disallow: *?s= Disallow: /category/$
Allow: *.css Disallow: /template/
Если нужно, чтобы все файлы .css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
 Файл robots txt для wordpress правильный и рабочий вариант для всех сайтов
Файл robots txt для wordpress правильный и рабочий вариант для всех сайтовAllow: *.css Allow: /template/*.css Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Например,
Sitemap: http://site.ru/sitemap.xml
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Host
Пример 1:Host: site.ru
Пример 2:Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
 Как приручить поискового бота: гайд по индексированию сайта
Как приручить поискового бота: гайд по индексированию сайтаПример 1:Crawl-delay: 3
Пример 2:Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Пример 1:
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Пример 2:
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
User-agent: * Disallow: /
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
 Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
- Закройте от индексирования админку сайта
- Закройте от индексирования личный кабинет, авторизацию, регистрацию
- Закройте от индексирования корзину, формы заказа, данные по доставке и заказам
- Закройте от индексирования ajax, json-скрипты
- Закройте от индексирования папку cgi
- Закройте от индексирования плагины, темы оформления, js, css для всех роботов, кроме Яндекса и Google
- Закройте от индексирования функционал поиска
- Закройте от индексирования служебные разделы, которые не несут никакой ценности для сайта в поиске (ошибка 404, список авторов)
- Закройте от индексирования технические дубли страниц, а также страницы, на которых весь контент в том или ином виде продублирован с других страниц (календари, архивы, RSS)
- Закройте от индексирования страницы с параметрами фильтров, сортировки, сравнения
- Закройте от индексирования страницы с параметрами UTM-меток и сессий
- Проверьте, что проиндексировано Яндексом и Google с помощью параметра «site:» (в поисковой строке наберите «site:site.ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt
- Укажите Sitemap и Host
- По необходимости пропишите Crawl-Delay и Clean-Param
- Проверьте корректность robots.txt через инструменты Google и Яндекса (описано ниже)
- Через 2 недели перепроверьте, появились ли в поисковой выдаче новые страницы, которые не должны индексироваться. В случае необходимости повторить выше перечисленные шаги.
Пример robots.txt
# Пример файла robots.txt для настройки гипотетического сайта https://site.ru User-agent: * Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Crawl-Delay: 5 User-agent: GoogleBot Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif User-agent: Yandex Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif Clean-Param: utm_source&utm_medium&utm_campaign Crawl-Delay: 0.5 Sitemap: https://site.ru/sitemap.xml Host: https://site.ru
Как добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
- В Яндекс.Вебмастере — на вкладке Инструменты>Анализ robots.txt
- В Google Search Console — на вкладке Сканирование>Инструмент проверки файла robots.txt
Типичные ошибки в robots.txt
 В конце статьи приведу несколько типичных ошибок файла robots.txt
В конце статьи приведу несколько типичных ошибок файла robots.txt
- robots.txt отсутствует
- в robots.txt сайт закрыт от индексирования (Disallow: /)
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий
- директива Host прописана несколько раз
- в Host не указан протокол https
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта
P.S.
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях. Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots.txt для WordPress».
P.S.2
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
Что такое robots.txt и для чего он нужен? Как правильно настроить robots.txt для SEO-оптимизации вашего сайта? Полный разбор структуры, правил и директив, используемых в robots.txt, который заставит поисковые системы полюбить ваш ресурс!
Что такое robots.txt и для чего он нужен
Robots.txt — это обычный текстовый файл с расширением .txt, который содержит директивы и инструкции индексирования сайта, его отдельных страниц или разделов для роботов поисковых систем.
Robots.txt является первым файлом, к которому обращаются поисковые системы, чтобы понять, можно ли индексировать сайт. Данный файл располагается в корневой директории сайта и должен быть доступен в браузере по ссылке вида naked-seo.ru/robots.txt.
Давайте рассмотрим самый простой пример содержимого robots.txt, которое разрешает поисковым системам индексировать все разделы сайта:
User-agent: * Allow: /
Данная инструкция дословно говорит: всем роботам, читающим данную инструкцию (User-agent: *) разрешаю индексировать весь сайт (Allow: /).
 Зачем все эти сложности с инструкциями для роботов, и почему нельзя открывать сайт для индексации полностью?
Зачем все эти сложности с инструкциями для роботов, и почему нельзя открывать сайт для индексации полностью?
Представьте, что вы поисковый робот, которому нужно просмотреть миллиарды страниц по всем интернету, потом определить для каждой страницы запросы, которым они могут соответствовать и в конце проранжировать эту массу в поисковой выдаче. Согласитесь, задача не из легких. Для работы поисковых алгоритмов используются колоссальные ресурсы, которые, разумеется, ограничены.
Если помимо страниц, которые содержат полезный контент, и которые по задумке владельца сайта должны участвовать в выдаче, роботу придется просматривать еще кучу технических страниц, которые не представляют никакой ценности для пользователей, его ресурсы будут тратиться впустую. Вы только представьте, что только один единственный сайт может генерировать тысячи страниц результатов поиска по сайту, дублирующихся страниц или страниц, не содержащих контента вообще. А если этот объем масштабировать на всю сеть, то получатся гигантские цифры и соответствующие ресурсы, которые необходимо тратить поисковикам.
Наличие огромного количества бесполезного контента на вашем сайте может негативно сказаться на его представлении в поиске. Как бы вы отнеслись к человеку, который дал вам мешок орехов, но внутри оказалась только скорлупа и всего 2-3 орешка? Не трудно представить и позицию поисковиков при аналогии данной ситуации с вашим сайтом.
Кроме того, существует такое понятие, как краулинговый бюджет. Условно, это объем страниц, который может участвовать в поисковой выдаче от одного сайта. Этот объем, естественно, ограничен, но по мере роста проекта и повышения его качества, краулинговый бюджет может увеличиваться, но сейчас не об этом. Главное идея в том, в выдаче должны участвовать только страницы, которые содержат полезный контент, а весь технический «мусор» не должен засорять выдачу поисковым спамом.
Как создать файл robots.txt на своем сайте?
Для того, чтобы создать файл robots.txt, вам нужно открыть любой текстовый редактор, например, Блокнот, MS Word, SublimeText, NotePad++ и т.п. Прописать необходимые инструкции для вашего сайта и сохранить файл в формате .txt.
Далее данный файл необходимо загрузить в корневую директорию вашего сайта. Корневая директория, это папка, как правило, с названием вашего сайта в которой находятся файлы вашей CMS и индексный файл index.html. Загрузить файл robotx.txt на сервер можно с помощью панели управления сервером (напр. ISPmanager, Cpannel), с помощью FTP-клиента (напр. FileZilla, TotalCommander), через консоль, либо через административную панель сайта, если CMS позволяет это сделать.
Некоторые системы управления сайтами имеют встроенный функционал, который позволяет создать robots.txt из админки сайта, либо с помощью дополнительных плагинов или модулей. Каким способом создавать robots.txt — нет абсолютно никакой разницы. Проверить корректность и доступность вашего файла robots вы можете с помощью сервиса в Яндекс.Вебмастере.
Правильная настройка robots.txt для сайта
Правильная настройка файла robots.txt помогает улучшить представление сайта в результатах поиска, пресекает попадание в поиск спама и частной информации. Однако стоит помнить, что robots.txt является общедоступным файлом, поэтому не следует хранить в нем пароли и другую конфиденциальную информацию, которая может использоваться как уязвимость против вашего ресурса.
Правильная структура robots.txt
Давайте рассмотрим сокращенный шаблон структуры robots.txt типичного сайта:
User-agent: Yandex Disallow: /admin Disallow: *?s= Disallow: *?p= User-agent: Googlebot Disallow: /admin Disallow: *?s= Disallow: *?p= User-agent: * Disallow: /admin Disallow: *?s= Disallow: *?p= Sitemap: https://site.ru/sitemap.xml
Как вы видите, файл robots.txt состоит из блоков с инструкциями. Начинается он с директивы User-agent, которая указывает для какого именно робота будут прописаны нижеследующие инструкции.
Примеры директив User-agent для разных поисковых роботов:
# Для всех роботов User-agent: * # Для роботов Яндекса User-agent: Yandex # Для всех роботов Google User-agent: Googlebot
Как правило, в большинстве файлов robots.txt используются 3 вышеперечисленных директивы User-agent, однако, существуют отдельные директивы, например, для роботов индексирующих изображения на сайте (YandexImages и Googlebot-Image), в которых можно прописать отдельные инструкции. Например:
#Разрешаем роботу Яндекса индексацию всего сайта User-agent: Yandex Allow: / #Разрешаем роботу Google индексацию всего сайта User-agent: Googlebot Allow: / #Запрещаем индексацию сайта всем остальным роботам User-agent: * Disallow: /
После каждой директивы User-agent идут непосредственные команды для каждого поискового робота. В большинстве случаев используются команды Disallow и Allow. Команда Disallow запрещает роботам индексирование определенных страниц, команда Allow, наоборот, разрешает.
Также в структуре присутствуют 2 обязательных директорий: Host и Sitemap. Директива Host указывает на главное зеркало сайта (УСТАРЕЛО — https://yandex.ru/blog/platon/pereezd-sayta-posle-otkaza-ot-direktivy-host), директива Sitemap указывает на xml карту сайта. Более подробно мы рассмотрим каждую директорию и возможности их применения далее. А сейчас остановимся на синтаксисе и правилах составления robots.txt.
Синтаксис и правила настройки robots.txt
Существуют определенные синтаксические и логические правила, которые влияют на корректность работы вашего robots.txt. Давайте рассмотрим их:
- По-умолчанию robots.txt разрешает индексировать все. Данное правило работает при отсутствии robots.txt на сервере, при пустом содержимом файла, при слишком большом файле размером более 32 кб, при недоступности файла (напр. код ответа 404);
- Название файла «robots.txt». Не допускается использование заглавных букв. Имя файла пишется на латинице;
- Каждая директива в файле начинается с новой строки. Не указывайте более одной инструкции в строке;
- Пробел как знак в robots.txt не имеет значения. Нет никакой разницы в количестве пробелов и их месте в файле, однако, составляйте robots.txt таким образом, чтобы вам самим было легко в нем ориентироваться;
- Инструкция не имеет закрывающих символов. В конце директивы не нужно ставить точку или точку с запятой;
- Допускается комментирование в файле. Это необходимо для удобства оптимизатора, чтоб тот мог оставлять информацию, объясняющую для чего он открыл/закрыл от индексации определенные страницы. Комментарий начинается со знака #;
- Пустой перенос строки используется только в конце директивы User-agent. В соответствие со стандартом пустой перенос строки может трактоваться как окончание инструкций по конкретному User-agent. Также использование нового User-aget без переноса строки может игнорироваться;
- В строке с директивой указывается только 1 параметр. Все последующие параметры прописываются с новой строки с указанием директивы.
- Названия директив пишутся на с заглавной буквы на латинице. Например, правильно «Dissalow», а не «DISALLOW»;
- Символ / используется при написании статических страниц. Например, «Disallow: /wp-admin» запрещает индексацию административной панели WordPress по данному адресу.
- Последовательность директив. Порядок следования директив в User-aget не влияет на их использование поисковым роботом. При конфликте инструкций Disallow и Allow предпочтение отдается директиве Allow.
Не стоит также вписывать в robots.txt запреты для каждой отдельно взятой страницы. Такая практика допустима, но это, скорее, исключения из правил. Подбирайте общие инструкции, которые будут захватывать сразу все типовые url вашего сайта. Идеальный robots.txt — это краткий по написанию, но обширный по смыслу файл.
Использование спецсимволов * и $ в robots.txt
При использовании директив Allow и Disallow в их параметрах можно использовать специальные символы * и $. Спецсимвол * означает любую последовательность символов в параметре. Например:
User-agent: * Disallow: /wp-content/*.txt #Зпрещает индексирование /wp-content/test.txt и wp-conten/upload/readme.txt и т.д. Disallow: /*blog #Зпрещает индексирование /blog и /main/blog и т.д. Disallow: *?p= #Зпрещает индексирование страниц пагинации на всем сайте
По-умолчанию на конце каждого параметра используется спецсимвол *. В свою очередь спецсимвол $ позволяет уточнить параметры индексирования. Например:
User-agent: * Disallow: /blog #Зпрещает индексирование /blog и /blog/h1 и т.д. Disallow: /blog$ #Зпрещает индексирование /blog, но разрешает /blog.html и /blog/h1 и т.д.
Запрет индексации в файле robots.txt — Disallow
Disallow — наиболее часто используемая директива в robots.txt. В ней необходимо указывать:
- страницы с приватными данными, которых не должно быть в индексе;
- страницы пагинации;
- страницы с результатами поиска по сайту;
- дублирующиеся страницы;
- всевозможные логи;
- технические страницы;
- сервисные страницы с параметрами.
Разрешить индексацию robots.txt — Allow
Allow — это директива разрешающая поисковому роботу обход страниц. Она является противоположностью директиве Disallow. В ней, как и в Disallow возможно использование спецсимволов * и $.
Давайте рассмотрим пример использования директивы Allow:
User-agent: * Disallow: / Allow: /blog
Данные инструкции разрешают обход раздела /blog, при этом весь остальной сайт остается недоступен для индексирования.
Пустой «Disallow: » = «Allow: /». Обе директивы разрешают полный обход сайтаПустой «Allow: » = «Disallow: /». Обе директивы полностью запрещают обход сайта.Эта информация дана для справки. Широкого практического применения она не получает.
Главное зеркало сайта в robots.txt — Host
С марта 2018 года Яндекс отказался от директивы Host. Ее функции полностью перешли на раздел «Переезд сайта в Вебмастере» и 301-редирект.
Директива Host указывала поисковому роботу Яндекса на главное зеркало сайта. Если ваш сайт был доступен по нескольким разным адресам, например, с www и без www, вам необходимо было настроить 301 редирект на главный адрес и указать его в директиве Host.
Данная директива была полезна при установке SSL-сертификата и переезде сайта с http на https. В директиве Host адрес сайта при наличии SSL-сертификата указывался с https.
Директива Host указывалась в User-agent: Yandex только 1 раз. Например для нашего сайта это выглядело вот так:
User-agent: Yandex Host: https://naked-seo.ru
В данном примере указано, что главным зеркалом сайта Naked SEO является ни www.naked-seo.ru, ни http://naked-seo.ru, а https://naked-seo.ru.
Карта сайта в robots.txt — Sitemap.xml
Директива Sitemap указывает поисковым роботам путь на xml карту сайта. Этот файл невероятно важен для поисковых систем, так как при обходе сайта они, в первую очередь, обращаются к нему. В данном файле представлена структура сайта со всем внутренними ссылками, датами создания страниц, приоритетами индексирования.
Пример robots.txt с указанием адреса карты сайта на нашем сайте:
User-agent: * Sitemap: https://naked-seo.ru/sitemal.xml
Директива Clean-param в robots.txt
Директива Clean-param позволяет запретить поисковым роботом обход страниц с динамическими параметрами, контент которых не отличается от основной страницы. Например, многие интернет-магазины используют параметры в url-адресах, которые передают данные по источникам сессий, а также персональные идентификаторы пользователей.
Чтобы поисковые роботы не обходили данные страницы, и лишний раз не нагружали ваш сервер, используйте директиву Clean-param, которая позволит оставить в выдаче только исходный документ.
Давайте рассмотрим использование данной директивы на примере. Предположим, что наш сайт собирает данные по пользователям на страницах:
https://naked-seo.ru/books/get_book.pl?userID=1&source=site_1&book_id=3 https://naked-seo.ru/books/get_book.pl?userID=2&source=site_2&book_id=3 https://naked-seo.ru/books/get_book.pl?userID=3&source=site_3&book_id=3
Параметр userID, который содержится в каждом url-адресе показывает персональный идентификатор пользователя, а параметр source показывает источник, из которого посетитель попал к нам на сайт. По трем разным url-адресам пользователи видят один и тот же контент book_id=3. В данном случае нам необходимо использовать директиву Clean-param следующим образом:
User-agent: Yandex Clean-param: userID /books/get_book.pl Clean-param: source /books/get_book.pl
Данные директивы помогут поисковому роботу Яндекса свести все динамические параметры в единую страницу:
https://naked-seo.ru/books/get_book.pl?&book_id=3
Директива Crawl-delay в robots.txt
Данная директива ограничивает количество посещений одного робота в интервал времени, другими словами создает тайм-аут сессии. Использование директивы Crawl-delay является хорошей практикой, если поисковые роботы слишком часто заходят на ваш сайт и создают ненужную нагрузку на сервер.
Пример использования директивы:
User-agent: Yandex Crawl-delay: 2 #создает тайм-аут в 2 секунды
Комментарии в robots.txt
Комментарии в файле robots.txt пишутся после знака # и игнорируются поисковыми системами. Как правило, комментарии используются для обозначения причин открытия или закрытия для индексации определенных страниц, чтобы в будущем оптимизатору были понятны причины тех или иных правок в файле.
В данной статье вы уже встречались с комментирование, которое поясняло использование директив. Вот еще один пример:
Как проверить robots.txt?
После того как вы загрузили файл robots.txt на свой сервер, обязательно проверьте его доступность, корректность и наличие ошибок в нем.
Как проверить robots.txt на сайте?
Если вы все сделали правильно, и загрузили данный файл в корень вашего сервера, то он станет доступен по ссылке вида site.ru/robots.txt. Данный файл, как мы уже говорили, является публичным. Поэтому вы можете посмотреть и проанализировать robots.txt абсолютно у любого сайта.
Как проверить robots.txt на наличие ошибок
Вы можете проверить robots.txt на наличие ошибок:
В панели Вебмастера Яндекс — https://webmaster.yandex.ru/tools/robotstxt/
И в Google Search Console — https://www.google.com/webmasters/tools/robots-testing-tool
Robots.txt в Яндекс и Google
У большинства оптимизаторов, которые первый раз сталкиваются с файлом robots.txt возникает вполне закономерный вопрос: «Почему нельзя указать User-agent: * и не прописывать для каждого робота одинаковые правила?». Конечно, так сделать можно, но возникает неопределенность. Во-первых, только Яндекс поддерживает директиву Host, которая указывает на главное зеркало сайта. Использование данной директивы для всех роботов бессмысленно (УСТАРЕЛО — https://yandex.ru/blog/platon/pereezd-sayta-posle-otkaza-ot-direktivy-host). Во-вторых, существует субъективное мнение, что поисковые системы Яндекс и Google приветствуют указание именно их робота в User-agent, а не использование директивы общего плана.
Заключение: советы Вебмастерам
Совет #1
Если ваш сайт не индексируется поисковыми системами, или его страницы начали массово пропадать из поисковой выдачи, первым делом необходимо проверить файл robots.txt на предмет запрета индексации сайта. При необходимости снимите запрет на полезные страницы, которые должны участвовать в выдаче.
Если файл robots.txt не запрещает индексирование сайта, проверьте содержимое мета-тегов в head вашего сайта, адресованных поисковым роботам. Обратите внимание на наличие на вашем сайте следующих тегов:
Наличие данных тегов может негативно повлиять на представление вашего сайта в поисковых системах.
Совет #2
Хотя бы 1 раз в 2-3 недели заглядывайте в Яндекс Вебмастер в разделы «Индексирование — Статистика обхода» и «Индексирование — Страницы в поиске». Отслеживайте страницы, которые обходит поисковый робот на вашем сайте.
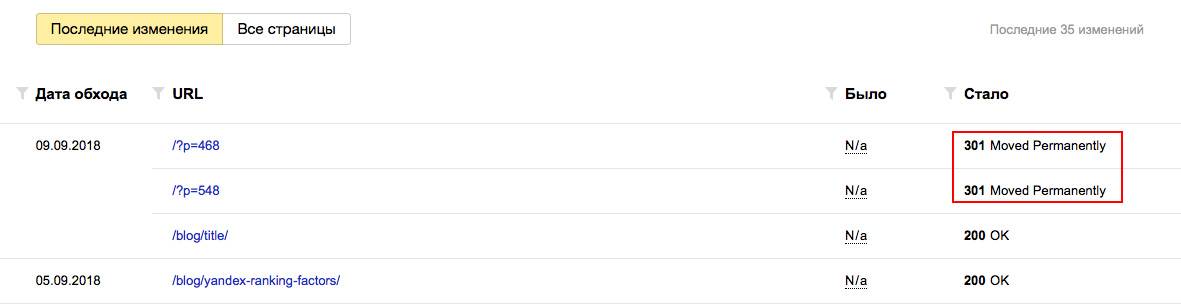
Если робот обходит технические страницы, или страницы, которые отвечают редиректом, их следуют запретить директивой Disallow в robots.txt. Таким образом вы сузите объем страниц, который необходимо обойти поисковому роботу и повысите эффективность индексации своего сайта.
Аналогична ситуация с разделом «Страницы в поиске». С его помощью вы можете не только отследить документы, которые больше не участвуют в поиске, но и проверить свой сайт на предмет наличия поискового спама. Если в данном разделе вы также найдете технические страниц, либо сервисные страницы с параметрами, которые не должны принимать участие в ранжировании, добавьте запрет на их обход в robots.txt.
Заключение
Файл robots.txt является одним из важнейших инструментов SEO-оптимизации. Через него можно напрямую влиять на индексирование абсолютно любых страниц и разделов сайта. Грамотно составленный robots.txt поможет вам сэкономить место в ограниченном краулинговом бюджете, избавит поисковые роботы от переобхода сотен ненужных технических страниц, избавит выдачу от поискового спама, а ваш сервер от излишней нагрузки. Создавайте robots.txt с умом!
Если у вас возникли вопросы по данной статье — задайте их в комментариях.Не забывайте подписываться на блог и получать актуальную информацию из мира интернет-маркетинга.
Одной из важнейших вещей при создании и оптимизации сайта для поисковых систем считают Robots.txt. Небольшой файлик, где прописаны правила индексирования для поисковых роботов.
Если файл будет настроен неправильно, то сайт может неправильно индексироваться и терять большие доли трафика. Грамотная настройка наоборот позволяет улучшить SEO, и вывести ресурс в топы.
Сегодня мы поговорим о настройке Robots.txt для WordPress. Я покажу вам правильный вариант, который сам использую для своих проектов.
Содержание
Что такое Robots.txt
Как я уже и сказал, robots.txt — текстовой файлик, где прописаны правила для поисковых систем. Стандартный robots.txt для WordPress выглядит следующим образом:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Именно в таком виде он создается плагином Yoast SEO. Некоторые считают, что этого хватит для правильной индексации. Я же считаю, что нужна более детальная проработка. А если речь идет о нестандартных проектах, то проработка нужна и подавно. Давайте разберемся в основных директивах:
| Директива | Значение | Пояснение |
| User-agent: | Yandex, Googlebot и т.д. | В этой директиве можно указать к какому конкретно роботу мы обращаемся. Обычно используются те значения, которые я указал. |
| Disallow: | Относительная ссылка | Директива запрета. Ссылки, указанные в этой директиве будут игнорироваться поисковыми системами. |
| Allow: | Относительная ссылка | Разрешающая директива. Ссылки, которые указаны с ней будут проиндексированы. |
| Sitemap: | Абсолютная ссылка | Здесь указывается ссылка на XML-карту сайта. Если в файле не указать эту директиву, то придется добавлять карту вручную (через Яндекс.Вебмастер или Search Console). |
| Crawl-delay: | Время в секундах (пример: 2.0 — 2 секунды) | Позволяет указать таймаут между посещениями поисковых роботов. Нужна в случае, если эти самые роботы создают дополнительную нагрузку на хостинг. |
| Clean-param: | Динамический параметр | Если на сайте есть параметры вида site.ru/statia?uid=32, где ?uid=32 — параметр, то с помощью этой директивы их можно скрыть. |
В принципе, ничего сложного. Дам дополнительные пояснения по директивам Clean-param (откройте вкладку).
Параметры, как правило, используются на динамических сайтах. Они могут передавать поисковым системам лишнюю информацию — создавать дубли. Чтобы избежать этого, мы должны указать в Robots.txt директиву Clean-param с указанием параметра и ссылки, к которой это параметр применяется.
В нашем примере site.ru/statia?uid=32 — site.ru/statia — ссылка, а все, что после знака вопроса — параметр. Здесь это uid=32. Он динамический, и это значит, что параметр uid может принимать другие значения.
Например, uid=33, uid=34…uid=123434. В теории их может быть сколько угодно, поэтому мы должны закрыть от индексации все параметры uid. Для этого директива должна принять такой вид:
Clean-param: uid /statia # все параметры uid для statia будут закрыты
Более подробно о том, что такое Robots.txt можно узнать из Яндекс.Помощи. Или из этого видеоролика:
Базовый Robots.txt для WordPress
Совсем недавно я приобрел плагин Clearfy Pro для своих проектов. Там очень много разных функций, и одна из них — создание идеального Robots.txt. На самом деле насколько он идеален — я не знаю, вебмастера расходятся во мнениях.
Кто-то предпочитает делать более краткие версии роботса, указывая правила для всех поисковых систем сразу. Другие прописывают отдельные правила для каждого поисковика (в основном для Яндекса и Гугла).
Что из этого правильно — точно сказать не могу. Однако я предлагаю вам ознакомиться с базовой версией Robots.txt для WordPress от Clearfy Pro. Я немного подредактировал ее — указал директиву Sitemap. Удалил директиву Host.
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.php Disallow: /readme.html Disallow: /*? Disallow: /?s= Allow: /*.css Allow: /*.js Sitemap: https://site.ru/sitemap.xml
Не могу сказать, что это лучший вариант для блогов на ВП. Но во всяком случае, он лучше, чем то, что нам предлагает Yoast SEO по умолчанию.
Расширенный Robots.txt для WordPress
Теперь посмотрим на расширенную версию Robots.txt для WordPress. Наверняка вы знаете, что все сайты на WP имеют одинаковую структуру. Одинаковые названия папок, файлов и т.д. позволяют специалистам выявить наиболее приемлемый вариант роботса.
Читайте также: Самые лучшие SEO-оптимизированные шаблоны для WordPress
В этой статье я хочу представить вам свой вариант Robots.txt. Его я использую как для своих сайтов, так и для клиентских. Вы могли видеть такой вариант и на других сайтах, т.к. он обладает некоторой популярностью.
Итак, правильный Robots.txt для WordPress выглядит следующим образом:
User-agent: * # Для всех поисковых систем, кроме Яндекса и Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Disallow: /tag/ # Закрываем метки Disallow: /readme.html # Закрываем бесполезный мануал по установке WordPress (лежит в корне) Disallow: *?replytocom Allow: */uploads User-agent: GoogleBot # Для Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Disallow: /tag/ # Закрываем метки Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php User-agent: Yandex # Для Яндекса Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: /tag/ # Закрываем метки Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign Clean-Param: openstat Sitemap: https://site.com/sitemap_index.xml # Карта сайта, меняем site.com на нужный адрес.
Важно:Ранее в Robots.txt использовалась директива Host. Она указывала главное зеркало сайта. Теперь это делается при помощи редиректа. Подробнее об этом можно почитать в блоге Яндекса.
Комментарии (текст после #) можно удалить. Указываю Sitemap с https протоколом, т.к. большинство сайтов сейчас используют защищенное соединение. Если у вас нет SSL, то измените протокол на http.
Читайте также: Как правильно настроить WordPress
Обратите внимание на то, что я закрываю метки (теги). Делаю это потому, что они создают большое количество дублей. Это плохо сказывается на SEO, но если вы хотите открыть метки, тогда уберите строчку disallow: /tag/ из файла.
Заключение
В общем-то, вот так выглядит правильный Robots.txt для WordPress. Смело копируйте данные в файл и пользуйтесь. Отмечу, что этот вариант подходит только для стандартных информационных сайтов.
В других ситуациях может потребоваться индивидуальная проработка. На этом все. Спасибо за внимание. Буду благодарен, если вы включите уведомления через колокольчик и подпишитесь на почтовую рассылку. Тут будет круто :).
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Используемые источники:
- https://seogio.ru/robots-txt/
- https://naked-seo.ru/blog/robots-txt/
- https://awayne.biz/pravilnyy-robots-txt-dlya-wordpress/

 Настройка плагина Yoast SEO wordpress новая инструкция
Настройка плагина Yoast SEO wordpress новая инструкция Где настройки браузера в компьютере
Где настройки браузера в компьютере Как настроить главное зеркало сайта в Google Search Console и Яндекс.Вебмастер
Как настроить главное зеркало сайта в Google Search Console и Яндекс.Вебмастер Плагин All in One SEO Pack. Правильная настройка
Плагин All in One SEO Pack. Правильная настройка