Содержание
- 1 Как влияет robots.txt на индексацию сайта
- 2 Директивы robots.txt
- 3 Закрывающий robots.txt
- 4 Правильная настройка robots.txt
- 5 Пример robots.txt
- 6 Как добавить и где находится robots.txt
- 7 Как проверить robots.txt
- 8 Типичные ошибки в robots.txt
- 9 P.S.
- 10 P.S.2
- 11 Что такое Robots.txt
- 12 Базовый Robots.txt для WordPress
- 13 Расширенный Robots.txt для WordPress
- 14 Заключение
Как влияет robots.txt на индексацию сайта
Поисковые роботы будут индексировать ваш сайт независимо от наличия файла robots.txt. Если же такой файл существует, то роботы могут руководствоваться правилами, которые в этом файле прописываются. При этом некоторые роботы могут игнорировать те или иные правила, либо некоторые правила могут быть специфичными только для некоторых ботов. В частности, GoogleBot не использует директиву Host и Crawl-Delay, YandexNews с недавних пор стал игнорировать директиву Crawl-Delay, а YandexDirect и YandexVideoParser игнорируют более общие директивы в роботсе (но руководствуются теми, которые указаны специально для них).
Подробнее об исключениях:Исключения ЯндексаСтандарт исключений для роботов (Википедия)
Максимальную нагрузку на сайт создают роботы, которые скачивают контент с вашего сайта. Следовательно, указывая, что именно индексировать, а что игнорировать, а также с какими временны́ми промежутками производить скачивание, вы можете, с одной стороны, значительно снизить нагрузку на сайт со стороны роботов, а с другой стороны, ускорить процесс скачивания, запретив обход ненужных страниц.
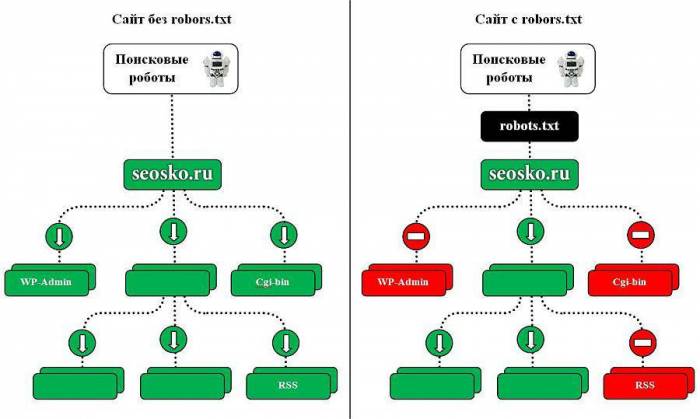
К таким ненужным страницам относятся скрипты ajax, json, отвечающие за всплывающие формы, баннеры, вывод каптчи и т.д., формы заказа и корзина со всеми шагами оформления покупки, функционал поиска, личный кабинет, админка.
Для большинства роботов также желательно отключить индексацию всех JS и CSS. Но для GoogleBot и Yandex такие файлы нужно оставить для индексирования, так как они используются поисковыми системами для анализа удобства сайта и его ранжирования (пруф Google, пруф Яндекс).
Директивы robots.txt
Директивы — это правила для роботов. Есть спецификация W3C от 30 января 1994 года и расширенный стандарт от 1996 года. Однако не все поисковые системы и роботы поддерживают те или иные директивы. В связи с этим для нас полезнее будет знать не стандарт, а то, как руководствуются теми или иными директивы основные роботы.
Давайте рассмотрим по порядку.
User-agent
Это самая главная директива, определяющая для каких роботов далее следуют правила.
Для всех роботов:User-agent: *
 Файл robots txt для wordpress правильный и рабочий вариант для всех сайтов
Файл robots txt для wordpress правильный и рабочий вариант для всех сайтовДля конкретного бота:User-agent: GoogleBot
Обратите внимание, что в robots.txt не важен регистр символов. Т.е. юзер-агент для гугла можно с таким же успехом записать соледующим образом:user-agent: googlebot
Ниже приведена таблица основных юзер-агентов различных поисковых систем.
| Бот | Функция |
|---|---|
| Googlebot | основной индексирующий робот Google |
| Googlebot-News | Google Новости |
| Googlebot-Image | Google Картинки |
| Googlebot-Video | видео |
| Mediapartners-Google | Google AdSense, Google Mobile AdSense |
| Mediapartners | Google AdSense, Google Mobile AdSense |
| AdsBot-Google | проверка качества целевой страницы |
| AdsBot-Google-Mobile-Apps | Робот Google для приложений |
| Яндекс | |
| YandexBot | основной индексирующий робот Яндекса |
| YandexImages | Яндекс.Картинки |
| YandexVideo | Яндекс.Видео |
| YandexMedia | мультимедийные данные |
| YandexBlogs | робот поиска по блогам |
| YandexAddurl | робот, обращающийся к странице при добавлении ее через форму «Добавить URL» |
| YandexFavicons | робот, индексирующий пиктограммы сайтов (favicons) |
| YandexDirect | Яндекс.Директ |
| YandexMetrika | Яндекс.Метрика |
| YandexCatalog | Яндекс.Каталог |
| YandexNews | Яндекс.Новости |
| YandexImageResizer | робот мобильных сервисов |
| Bing | |
| Bingbot | основной индексирующий робот Bing |
| Yahoo! | |
| Slurp | основной индексирующий робот Yahoo! |
| Mail.Ru | |
| Mail.Ru | основной индексирующий робот Mail.Ru |
| Rambler | |
| StackRambler | Ранее основной индексирующий робот Rambler. Однако с 23.06.11 Rambler перестает поддерживать собственную поисковую систему и теперь использует на своих сервисах технологию Яндекса. Более не актуально. |
Disallow и Allow
Но здесь не все так просто.
Во-первых, нужно знать дополнительные операторы и понимать, как они используются — это *, $ и #.
Примеры использования:
Disallow: *?s= Disallow: /category/$
Allow: *.css Disallow: /template/
Если нужно, чтобы все файлы .css были открыты для индексирования придется это дополнительно прописать для каждой из закрытых папок. В нашем случае:
 Как приручить поискового бота: гайд по индексированию сайта
Как приручить поискового бота: гайд по индексированию сайтаAllow: *.css Allow: /template/*.css Disallow: /template/
Повторюсь, порядок директив не важен.
Sitemap
Директива для указания пути к XML-файлу Sitemap. URL-адрес прописывается так же, как в адресной строке.
Например,
Sitemap: http://site.ru/sitemap.xml
Директива Sitemap указывается в любом месте файла robots.txt без привязки к конкретному user-agent. Можно указать несколько правил Sitemap.
Host
Пример 1:Host: site.ru
Пример 2:Host: https://site.ru
Crawl-delay
Директива для установления интервала времени между скачиванием роботом страниц сайта. Поддерживается роботами Яндекса, Mail.Ru, Bing, Yahoo. Значение может устанавливаться в целых или дробных единицах (разделитель — точка), время в секундах.
 Где настройки браузера в компьютере
Где настройки браузера в компьютереПример 1:Crawl-delay: 3
Пример 2:Crawl-delay: 0.5
Если сайт имеет небольшую нагрузку, то необходимости устанавливать такое правило нет. Однако если индексация страниц роботом приводит к тому, что сайт превышает лимиты или испытывает значительные нагрузки вплоть до перебоев работы сервера, то эта директива поможет снизить нагрузку.
Чем больше значение, тем меньше страниц робот загрузит за одну сессию. Оптимальное значение определяется индивидуально для каждого сайта. Лучше начинать с не очень больших значений — 0.1, 0.2, 0.5 — и постепенно их увеличивать. Для роботов поисковых систем, имеющих меньшее значение для результатов продвижения, таких как Mail.Ru, Bing и Yahoo можно изначально установить бо́льшие значения, чем для роботов Яндекса.
Clean-param
Это правило сообщает краулеру, что URL-адреса с указанными параметрами не нужно индексировать. Для правила указывается два аргумента: параметр и URL раздела. Директива поддерживается Яндексом.
Пример 1:
Clean-param: author_id http://site.ru/articles/
http://site.ru/articles/?author_id=267539 — индексироваться не будет
Пример 2:
Clean-param: author_id&sid http://site.ru/articles/
http://site.ru/articles/?author_id=267539&sid=0995823627 — индексироваться не будет
Яндекс также рекомендует использовать эту директиву для того, чтобы не учитывались UTM-метки и идентификаторы сессий. Пример:
Clean-Param: utm_source&utm_medium&utm_campaign
Другие параметры
В расширенной спецификации robots.txt можно найти еще параметры Request-rate и Visit-time. Однако они на данный момент не поддерживаются ведущими поисковыми системами.
Закрывающий robots.txt
Если вам нужно настроить, чтобы ваш сайт НЕ индексировался поисковыми роботами, то вам нужно прописать следующие директивы:
User-agent: * Disallow: /
Проверьте, чтобы на тестовых площадках вашего сайта были прописаны эти директивы.
Правильная настройка robots.txt
 Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Для России и стран СНГ, где доля Яндекса ощутима, следует прописывать директивы для всех роботов и отдельно для Яндекса и Google.
Чтобы правильно настроить robots.txt воспользуйтесь следующим алгоритмом:
- Закройте от индексирования админку сайта
- Закройте от индексирования личный кабинет, авторизацию, регистрацию
- Закройте от индексирования корзину, формы заказа, данные по доставке и заказам
- Закройте от индексирования ajax, json-скрипты
- Закройте от индексирования папку cgi
- Закройте от индексирования плагины, темы оформления, js, css для всех роботов, кроме Яндекса и Google
- Закройте от индексирования функционал поиска
- Закройте от индексирования служебные разделы, которые не несут никакой ценности для сайта в поиске (ошибка 404, список авторов)
- Закройте от индексирования технические дубли страниц, а также страницы, на которых весь контент в том или ином виде продублирован с других страниц (календари, архивы, RSS)
- Закройте от индексирования страницы с параметрами фильтров, сортировки, сравнения
- Закройте от индексирования страницы с параметрами UTM-меток и сессий
- Проверьте, что проиндексировано Яндексом и Google с помощью параметра «site:» (в поисковой строке наберите «site:site.ru»). Если в поиске присутствуют страницы, которые также нужно закрыть от индексации, добавьте их в robots.txt
- Укажите Sitemap и Host
- По необходимости пропишите Crawl-Delay и Clean-Param
- Проверьте корректность robots.txt через инструменты Google и Яндекса (описано ниже)
- Через 2 недели перепроверьте, появились ли в поисковой выдаче новые страницы, которые не должны индексироваться. В случае необходимости повторить выше перечисленные шаги.
Пример robots.txt
# Пример файла robots.txt для настройки гипотетического сайта https://site.ru User-agent: * Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Crawl-Delay: 5 User-agent: GoogleBot Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Disallow: *utm= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif User-agent: Yandex Disallow: /admin/ Disallow: /plugins/ Disallow: /search/ Disallow: /cart/ Disallow: */?s= Disallow: *sort= Disallow: *view= Allow: /plugins/*.css Allow: /plugins/*.js Allow: /plugins/*.png Allow: /plugins/*.jpg Allow: /plugins/*.gif Clean-Param: utm_source&utm_medium&utm_campaign Crawl-Delay: 0.5 Sitemap: https://site.ru/sitemap.xml Host: https://site.ru
Как добавить и где находится robots.txt
После того как вы создали файл robots.txt, его необходимо разместить на вашем сайте по адресу site.ru/robots.txt — т.е. в корневом каталоге. Поисковый робот всегда обращается к файлу по URL /robots.txt
Как проверить robots.txt
Проверка robots.txt осуществляется по следующим ссылкам:
- В Яндекс.Вебмастере — на вкладке Инструменты>Анализ robots.txt
- В Google Search Console — на вкладке Сканирование>Инструмент проверки файла robots.txt
Типичные ошибки в robots.txt
 В конце статьи приведу несколько типичных ошибок файла robots.txt
В конце статьи приведу несколько типичных ошибок файла robots.txt
- robots.txt отсутствует
- в robots.txt сайт закрыт от индексирования (Disallow: /)
- в файле присутствуют лишь самые основные директивы, нет детальной проработки файла
- в файле не закрыты от индексирования страницы с UTM-метками и идентификаторами сессий
- директива Host прописана несколько раз
- в Host не указан протокол https
- путь к Sitemap указан неверно, либо указан неверный протокол или зеркало сайта
P.S.
Если у вас есть дополнения к статье или вопросы, пишите ниже в комментариях. Если у вас сайт на CMS WordPress, вам будет полезна статья «Как настроить правильный robots.txt для WordPress».
P.S.2
Полезное видео от Яндекса (Внимание! Некоторые рекомендации подходят только для Яндекса).
<?// В этом файле есть те нужные стили которые в других файлах нет.
| SEO | – Читать 18 минут – | 23 мая 2018 |
Прочитать позже Иллюстрация: Наталья Сорока
Иллюстрация: Наталья Сорока Да-да, опять robots.txt — вы всё-всё знаете лучше меня. И я опять буду писать прописные истины, но какого же черта я это делаю? Я просто оставлю скрин переписки действующего сеошника с программистом (который, конечно же, «шарит в SEO»), после того, как я посоветовал их клиенту закрыть мусор от индексации простым правилом Disallow: *? :
Да-да, опять robots.txt — вы всё-всё знаете лучше меня. И я опять буду писать прописные истины, но какого же черта я это делаю? Я просто оставлю скрин переписки действующего сеошника с программистом (который, конечно же, «шарит в SEO»), после того, как я посоветовал их клиенту закрыть мусор от индексации простым правилом Disallow: *? : Я замазал фамилии, все же этика и все в этом духе. Но после таких перлов от людей, которые продвигают сайт за деньги и называют себя специалистами мне кажется статья более, чем актуальна :)Содержание1. Что такое robots.txt?1.1. Почему важно управлять индексацией 1.2. Что нужно закрывать в robots.txt 1.3. Влияние файла robots.txt на Яндекс и Google 1.4. Онлайн-генераторы 2. Структура и правильная настройка robots.txt 2.1. Директива User-agent 2.2. Директива Allow 2.3. Директива Disallow 2.4. Директива Host2.5. Директива Sitemap 2.6. Директива Clean-param 2.7. Директива Crawl-Delay 2.8. Дополнение3. 6 популярных косяков в robots.txt 4. Пример robots.txt 5. Проверка и валидация6. Файл robots.txt для популярных CMS7. Заключение Для тех, кто не любит читать — я снял короткое видео с пояснениями и основными моментами:#1
Я замазал фамилии, все же этика и все в этом духе. Но после таких перлов от людей, которые продвигают сайт за деньги и называют себя специалистами мне кажется статья более, чем актуальна :)Содержание1. Что такое robots.txt?1.1. Почему важно управлять индексацией 1.2. Что нужно закрывать в robots.txt 1.3. Влияние файла robots.txt на Яндекс и Google 1.4. Онлайн-генераторы 2. Структура и правильная настройка robots.txt 2.1. Директива User-agent 2.2. Директива Allow 2.3. Директива Disallow 2.4. Директива Host2.5. Директива Sitemap 2.6. Директива Clean-param 2.7. Директива Crawl-Delay 2.8. Дополнение3. 6 популярных косяков в robots.txt 4. Пример robots.txt 5. Проверка и валидация6. Файл robots.txt для популярных CMS7. Заключение Для тех, кто не любит читать — я снял короткое видео с пояснениями и основными моментами:#1
Что такое robots.txt?</h2>robots.txt — это простой текстовый файл, название которого пишется в нижнем регистре и лежит он в корневой директории сайта: Если вы правильно его разместили, то он откроется по адресу: site.ru/robots.txt*Чтобы найти все страницы сайта, которые закрыты в robots.txt, можно использовать «Аудит сайта» Serpstat.
Если вы правильно его разместили, то он откроется по адресу: site.ru/robots.txt*Чтобы найти все страницы сайта, которые закрыты в robots.txt, можно использовать «Аудит сайта» Serpstat.
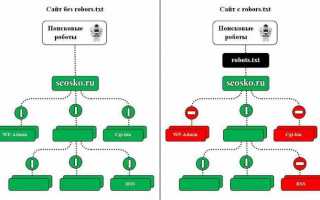
Почему важно управлять индексацией</h3>Если у вас сайт на голом HTML + CSS, т. е. вы каждую страничку верстаете вручную, не используете скрипты и базы данных (сайт из 100 страниц — это 100 HTML-файлов у вас на хостинге), то вам эта статья не нужна. В таких сайтах управлять индексацией незачем. Но у вас не простой сайт-визитка из пары страниц (хотя и такие уже давно создаются на CMS вроде WordPress/MODx и других) и вы работаете с любой CMS (а значит и с языками программирования, скриптами, базой данных и т. д.) — то столкнетесь с такими «прелестями», как: Основная проблема в том, что в индекс поисковых систем попадает то, что там быть не должно — страницы, не несущие никакой пользы людям и засоряющие поиск. Вроде бы не так страшно, место в Яндексе не закончится, но быстро закончится доверие поисковой системы к вашему ресурсу. Как следствие — понижение позиций и трафика, фильтры, депрессия и т. д.  Когда из 500 страничного сайта в индексе оказывается 3100 страницТак же есть такая штука, как краулинговый бюджет — определенное количество страниц, которые робот может просканировать за один раз. Он определяется для каждого сайта индивидуально. Имея кучи незакрытого мусора страницы могут дольше индексироваться из-за того, что им не хватило краулингового бюджета.
Когда из 500 страничного сайта в индексе оказывается 3100 страницТак же есть такая штука, как краулинговый бюджет — определенное количество страниц, которые робот может просканировать за один раз. Он определяется для каждого сайта индивидуально. Имея кучи незакрытого мусора страницы могут дольше индексироваться из-за того, что им не хватило краулингового бюджета. SEO-инсайты, которые можно достать из логов серверов
SEO-инсайты, которые можно достать из логов серверов
Что нужно закрывать в robots.txt</h3>Чаще всего в индекс попадает следующий хлам:1Страницы поиска. Если вы не собираетесь их модерировать и прорабатывать — закрывайте их от индексации.2Корзина магазина.3Страницы благодарности и оформления заказов.4Иногда имеет смысл закрывать страницы пагинации.5Сравнения товаров.6Сортировки.7Фильтры, если невозможно их оптимизировать и модерировать.8Теги, если вы не можете их оптимизировать и модерировать.9Страницы регистрации и авторизации.10Личный кабинет.11Списки желаний.12Профили юзеров.13Фиды.14Различные лэндинги, созданные только под акции и распродажи.15Системные файлы и каталоги.16Языковые версии, если они не оптимизированы.17Версии для печати.18Пустые страницы и т. д.
Влияние файла robots.txt на Яндекс и Google</h3>Яндекс пока считает правила, описанные в файле, как указания к действию — он не будет индексировать указанные страницы.Google же считает себя умнее и сам решает что и как ему индексировать. Однако если СРАЗУ закрыть страницы в robots.txt (до выпуска сайт в индекс), то вероятность того, что они попадут в Google намного ниже.Но как только на закрытые страницы пойдут ссылки или трафик — поисковая система сочтет их нужными для индексации.Потому в Google надежнее закрывать страницы от индексации через мета-тег robots: Как задать в robots.txt директивы для роботов Google и Яндекса
Как задать в robots.txt директивы для роботов Google и Яндекса
<meta><meta><title>…</title>Онлайн-генераторы</h3>По аналогии с sitemap.xml у многих людей может возникнуть мысль о генераторах. Они есть. Они бесплатно. Они нафиг никому не нужны. Для примера возьмем генератор PR-CY. Все, что он делает — подставляет за вас слово «Disallow» и «User-agent». Экономии времени — 0, пользы — 0, смысла использовать — тоже 0.  Ищем смысл онлайн-генераторов robots.txtПишем все руками, чаще всего достаточно юзер-агентов «*» и Yandex, остальные используйте при необходимости.#2
Ищем смысл онлайн-генераторов robots.txtПишем все руками, чаще всего достаточно юзер-агентов «*» и Yandex, остальные используйте при необходимости.#2
Структура и правильная настройка robots.txt</h2>Структура файла robots.txt имеет следующий вид:
- Указание робота
- Указание робота 2
- И т. д.
Порядок следования директив в файле не играет роли, т. к. поисковая система интерпретирует ваши правила в зависимости от длины префикса URL (от коротких к длинным). Для понимания: Также хочу заметить, что важен регистр написания: Catalog, CataloG и catalog — это 3 разных алиаса (псевдонима страницы). Давайте разбирать директивы.
Директива User-agent</h3>Здесь указывается робот, для которого будут актуальны правила, которые описаны ниже. Чаще всего встречаются записи: Я всегда делаю правила для 2 роботов * и Yandex, т. к. ранее были случаи, когда бот Яндекса просто проигнорировал правила в *. С тех пор прошло много времени, но перепроверять сие действие нет желания, проще сделать 2 юзер-агента. Для Яндекса у нас есть следующие юзер-агенты (если вы решите закрывать страницы именно для конкретного бота, а не всех):
- YandexBlogs — робот, индексирующий посты и комментарии;
- YandexBot — основной индексирующий робот;
- YandexCalendar — робот Яндекс.Календаря;
- YandexDirect — скачивает информацию о контенте сайтов-партнеров Рекламной сети, чтобы уточнить их тематику для подбора релевантной рекламы, интерпретирует robots.txt особым образом;
- YandexDirectDyn — робот генерации динамических баннеров, интерпретирует robots.txt особым образом;
- YaDirectFetcher — робот Яндекс.Директа, интерпретирует robots.txt особым образом;
- YandexImages — индексатор Яндекс.Картинок;
- YandexMarket — робот Яндекс.Маркета;
- YandexMedia — робот, индексирующий мультимедийные данные;
- YandexMetrika — робот Яндекс.Метрики;
- YandexNews — робот Яндекс.Новостей;
- YandexPagechecker — валидатор микроразметки.
Для Google:
- APIs-Google — агент пользователя, который API Google применяет для отправки push-уведомлений;
- Mediapartners-Google — робот-анализатор AdSense;
- AdsBot-Google-Mobile — проверяет качество рекламы на веб-страницах, предназначенных для устройств Android и IOS;
- AdsBot-Google — проверяет качество рекламы на веб-страницах, предназначенных для компьютеров;
- Googlebot-Image — робот индексирующий картинки;
- Googlebot-News — робот Google новостей;
- Googlebot-Video — робот Google видео;
- Googlebot — основной инструмент для сканирования контента в Интернете;
- Googlebot-Mobile — робот индексирующий сайты для мобильных устройств.
Директива Disallow</h3>Запрет указанного URL для индексации. Используется практически в каждом robots.txt, поскольку чаще нужно закрывать мусор, а не открывать отдельные части сайта. Пример использования: У нас есть поиск на сайте, который генерирует URL вида: Видим, что у него есть основа /search. Смотрим структуру сайта, чтобы убедиться, что с такой же основной нет ничего важного и закрывает весь поиск от индексации:
Disallow: /search Директива Host</h3>Раньше это был указатель на главное зеркало сайта. Как правило, директива Host указывается в самом конце файла robots.txt:
User-agent: Yandex Disallow: /cgi-bin Host: site.ru Директива Sitemap</h3>Важно! Указывайте именно абсолютный путь.Указывается он так:
Sitemap: https://site.ru/site_structure/my_sitemaps1.xmlДиректива Clean-param</h3>Если у вас на сайте есть динамические параметры, которые не влияют на содержимое страницы (идентификаторы сессий, пользователей, рефереров и т. д.) — можно их описать именно этой директивой.Т. е. вы дадите понять роботу Яндекса, чтобы он не напрягался лишний раз и не сканировал одинаковые страницы, а уделял больше времени важным документам.Пример от Яндекса:Например, на сайте есть страницы:
- www.example.com/some_dir/get_book.pl?ref=site_1&book_id=123
- www.example.com/some_dir/get_book.pl?ref=site_2&book_id=123
Параметр ref используется только для того, чтобы отследить с какого ресурса был сделан запрос. Он не меняет содержимое — по всем трем адресам будет показана одна и та же страница с книгой book_id=123. Тогда, если указать директиву следующим образом: Как настроить обработку GET-параметров в robots.txt с помощью директивы Clean-param
Как настроить обработку GET-параметров в robots.txt с помощью директивы Clean-param
User-agent: Yandex Clean-param: ref /some_dir/get_book.plробот Яндекса сведет все адреса страницы к одному: Если на сайте доступна такая страница, именно она будет участвовать в результатах поиска. P.S. От себя еще добавлю, что данная директива на практике используется нечасто. В основном для UTM-меток.
Директива Crawl-Delay</h3> Реализация: P.S. Я никогда не парюсь и оставляю все на усмотрение Яндекса. Проблем пока не наблюдал.
Реализация: P.S. Я никогда не парюсь и оставляю все на усмотрение Яндекса. Проблем пока не наблюдал.
Дополнение</h3>Символ # — комментирование. Все, что находится после данного символа (в этой же строке) — игнорируется. Символ * — любая последовательность символов. Пример использования: У вас есть товары и в каждом товаре есть отзывы: У нас отличается товар, но отзывы имеют одинаковый алиас. Закрыть отзывы с помощью Disallow: /reviews мы не можем, т .к. у нас префикс начинается не с /reviews, а с /product-1, /product-2 и т. д. Следовательно, нам нужно как бы пропустить названия продуктов:
Disallow: /*/reviews Символ $ — означает конец строки. Чтобы объяснить суть его работы вернемся к примеру выше. Нам также нужно закрыть отзывы, но оставить открытой страницы отзывы от Жорика и его друзей:
- Site.ru/product-1/reviews/George
- Site.ru/product-1/reviews/Huan
Если мы используем наш вариант с Disallow: /*/reviews — отзыв Жорика погибнет, как и всех его друзей. Но Жорик оставил хороший отзыв!Решение:
Disallow: /*/reviews/$#3
6 популярных косяков в robots.txt</h2>На самом деле нет ничего сложного в ковырянии robots.txt. Важно пользоваться валидатором, знать директивы и следить за регистром. Однако стоит избегать некоторых ошибок:#1
Пустой Disallow</h3>Удобно копировать Disallow, когда пишешь его кучу раз, но потом забываешь удалить пустой и остается строка:
Disallow: Disallow без указания значения = разрешение к индексации сайта.#2
Кривое закрытие от Яндекса</h3>Видел, как закрывают сайт от Яндекса методом:
Disallow: YandexНазвание робота всегда пишется в User-Agent.#3
Ошибка названия</h3>Написать Robots.txt, т. е. нарушить регистр 1 буквы. Все должно быть в нижнем регистре. Сюда же идет написание robots.txt.Всегда пишется robots.txt#4
Перечисление папок</h3>Перечисления в директиве Disallow различных каталогов через запятую или пробел. Это так не работает.#5
Перечисление файлов</h3>Перечисление файлов, которые нужно закрыть.Достаточно закрыть папку, и все файлы в ней также будут закрыты для индексации.#6
Забивание на проверки</h3>Есть люди, которые закрывают страницы, используют сложные правила, но при этом забивают на проверку своего robots.txt в валидаторе, а иногда даже не могут проверить в нем определенные варианты.Яркий пример этого был в начале поста. Есть много случаев, когда оптимизаторы, не перепроверив данные, закрывали целые разделы сайта. Всегда используйте валидатор!#4
Пример robots.txt</h2>В качестве примера я возьму свой блог, и его robots и дам комментарии к каждой строке. Т. к. директивы для Яндекса и прочих роботов одинаковы, я прокомментирую только первую часть. Данный файл не менялся с момента создания блога, потому есть устаревшие моменты:
User-agent: Yandex # Обращение к роботу Яндекса Disallow: /wp-content/uploads/ # Закрываем всю папку Allow: /wp-content/uploads/*/*/ # Открываем папки картинок вида /uploads/close/open/ Disallow: /wp-login.php # Закрытие файла. Делать не нужно Disallow: /wp-register.php Disallow: /xmlrpc.php Disallow: /template.html Disallow: /cgi-bin # Закрываем папку Disallow: /wp-admin # Закрываем все служебные папки в CMS Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-content/themes Disallow: /wp-trackback Disallow: /wp-feed Disallow: /wp-comments Disallow: */trackback # Закрываем URL содержащие /trackback Disallow: */feed # Закрываем URL содержащие /feed Disallow: */comments # Закрываем URL содержащие /comments Disallow: /archive # Закрываем архивы Disallow: /?feed= # Закрываем фиды Disallow: /?s= # Закрываем URL поиска по сайту Allow: /wp-content/themes/RomanusNew/js* # Открываем только папку js Allow: /wp-content/themes/RomanusNew/style.css # Открываем файл style.css Allow: /wp-content/themes/RomanusNew/css* # Открываем только папку css Allow: /wp-content/themes/RomanusNew/fonts* # Открываем только папку fonts Host: romanus.ru # Указание главного зеркала, уже неактуально Sitemap: http://romanus.ru/sitemap.xml # Абсолютная ссылка на карту сайта #5
Проверка и валидация</h2>Не стоит публиковать файл robots.txt сразу на сайт, лучше зайти в Яндекс Вебмастер и проверить его корректность, а также что именно он закрывает: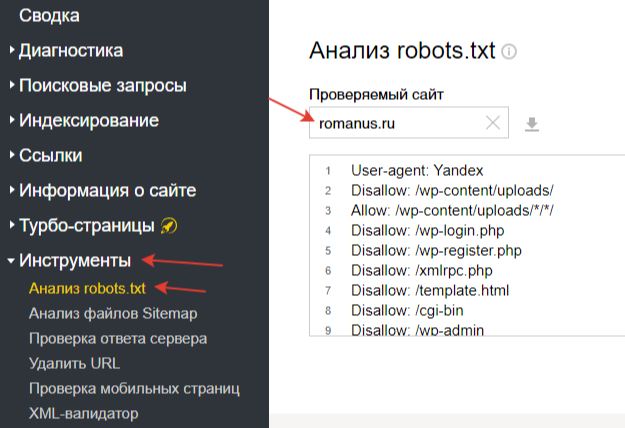 Давайте проверим самые «скользкие» моменты:
Давайте проверим самые «скользкие» моменты:
Disallow: /wp-content/uploads/ Allow: /wp-content/uploads/*/*/ Disallow: */trackback Disallow: /?feed= Disallow: /?s= Allow: /wp-content/themes/RomanusNew/js* Allow: /wp-content/themes/RomanusNew/style.css Итого: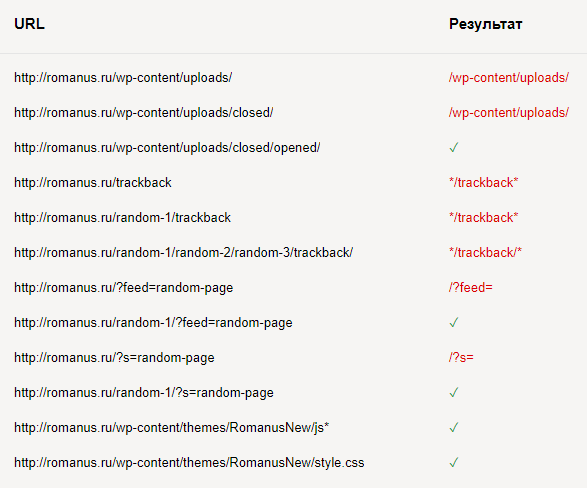 Отлично, все, что нужно — закрыто. Открыты нужные файлы и папки. Так же подсвечивается по какому правилу блочится каждый URL. Особо внимательные могли увидеть, что открыт для индексации URL http://romanus.ru/random-1/?s=random-page. Дело в том, что у меня URL поиска имеют вид строго site.ru/?s=… Они не могут быть в какой-то папке. В другом случае, мне пришлось бы заменить правило Disallow: /?s= на Disallow: */?s=#6
Отлично, все, что нужно — закрыто. Открыты нужные файлы и папки. Так же подсвечивается по какому правилу блочится каждый URL. Особо внимательные могли увидеть, что открыт для индексации URL http://romanus.ru/random-1/?s=random-page. Дело в том, что у меня URL поиска имеют вид строго site.ru/?s=… Они не могут быть в какой-то папке. В другом случае, мне пришлось бы заменить правило Disallow: /?s= на Disallow: */?s=#6
Файл robots.txt для популярных CMS</h2> Сразу скажу, что не стоит в лоб использовать любые найденные в сети файлы robots.txt. Это относится к любым файлам и любой информации. Поэтому если у вас окажется немного нестандартное решений или дополнительные плагины, которые меняют URL и т. д., то могут быть проблемы с индексацией и закрытием лишнего. Поэтому предлагаю ознакомиться и взять за основу robots.txt для следующих CMS:
Заключение</h2>Если подвести итог, то алгоритм работы с файлом robots.txt:1Создать и разместить в корне сайта.2Взять за основу типовой robots.txt для своей CMS.3Добавить в него типовые мусорные страницы, описанные в статье.4Просканировать свой сайт любым краулером (типа Screaming Frog SEO Spider или Netpeak Spider), чтобы посмотреть на общую картину URL и того, что вы закрыли. Возможно встретятся еще мусорные страницы.5Пустить сайт в индекс.6Мониторить Яндекс Вебмастер и Google Webmasters на предмет мусорных страниц и оперативно их закрывать от индексации (и делать это не только с помощью robots.txt).
Рекомендуемые статьи
Игорь Шулежко: «Pinterest и другие источники трафика»
11 мая 2018 г.
Что учитывать при анализе SERP
07 мая 2018 г.
Полный гайд по Google Analytics
26 апр. 2018 г.
Кейсы, лайфхаки, исследования и полезные статьи
Не успеваешь следить за новостями? Не беда! Наш любимый редактор Анастасия подберет материалы, которые точно помогут в работе. Присоединяйся к уютному комьюнити 🙂
Нажимая кнопку, ты соглашаешься с нашей политикой конфиденциальности.
Влад Наумов
Первый из популярных косяков содержит косяк.
Директива «Disallow: » ≠ «Disallow: / «
http://prntscr.com/jlr37khttp://prntscr.com/jlr3wphttp://prntscr.com/jlr4he
Romanus
Disallow без указания значения = разрешение к индексации сайта.
Валерия Очереднюк
Исправили.
Пані Яновська
Когда Вы уже начнете понимать разницу между сканированием и индексированием? Уже и справку Гугла по robots.txt исправили, а все пишут запрещает индексирование. Директивы файла robots.txt носят рекомендационный характер и только на сканирование.
Romanus
Для Google носит рекомендательный характер — об этом и сказано в статье. Для Яндекса — наоборот.
Пані Яновська
Romanus
https://yandex.ru/support/w… — справка Яндекса. В видео говорить «запрет на индексацию всего сайта». Логично, страницы, которые краулер не может просканировать, индексатор соответственно не может проиндексировать. Но конечное действие в случае с Яндексом — страница с запретом в robots.txt не попадет в индекс.
В случае Google — всё иначе, о чем указано в статье.
Насчет новой консоли это вы про ребрендинг из GWT в Google Search Console в 2015 (или около того)? Если да, то Google мог игнорировать robots.txt еще и раньше.
Читатель
Дякую, мріяв про таку статтю
Andrii Maselko
Подскажите плизз вот что, не могу разобраться.
3. Также и картинки чтобы индексировались нужно открыть для индексации. Дело в том что при публикации картинок Вордпресс автоматически создает свою страницу для каждой картинки (URL) такая страница если на нее зайти по прямой ссылке пустая только с фотографией. Так вот что делать? Плагин Yoast рекомендует: если вы никогда не используете эти URL, лучше деактивировать их и перенаправить их на сам медиа-объект. Т.е. они рекомендуют перенаправить URL вложений на файл вложения. Они делают это если включить перенаправление. Я сейчас отключил это перенаправление и у меня появилась дополнительная карта сайта со страницами фотографий, но интересно что почему то не все фотографии. Вот страница: https://www.nsdancing.com/a…Что посоветуете делать?
5. Как рекомендуют спецы по настройке файла для robots.txt всякий раз когда я вставляю команду Allow: /wp-admin/admin-ajax.php то позже в Гугл сорч консоли появляется ошибка с ответом сервера 400 именно на эту команду. Что мне делать?
Пожалуйста подскажите как лучше. Спасибо!
Одной из важнейших вещей при создании и оптимизации сайта для поисковых систем считают Robots.txt. Небольшой файлик, где прописаны правила индексирования для поисковых роботов.
Если файл будет настроен неправильно, то сайт может неправильно индексироваться и терять большие доли трафика. Грамотная настройка наоборот позволяет улучшить SEO, и вывести ресурс в топы.
Сегодня мы поговорим о настройке Robots.txt для WordPress. Я покажу вам правильный вариант, который сам использую для своих проектов.
Содержание
Что такое Robots.txt
Как я уже и сказал, robots.txt — текстовой файлик, где прописаны правила для поисковых систем. Стандартный robots.txt для WordPress выглядит следующим образом:
User-agent: * Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php
Именно в таком виде он создается плагином Yoast SEO. Некоторые считают, что этого хватит для правильной индексации. Я же считаю, что нужна более детальная проработка. А если речь идет о нестандартных проектах, то проработка нужна и подавно. Давайте разберемся в основных директивах:
| Директива | Значение | Пояснение |
| User-agent: | Yandex, Googlebot и т.д. | В этой директиве можно указать к какому конкретно роботу мы обращаемся. Обычно используются те значения, которые я указал. |
| Disallow: | Относительная ссылка | Директива запрета. Ссылки, указанные в этой директиве будут игнорироваться поисковыми системами. |
| Allow: | Относительная ссылка | Разрешающая директива. Ссылки, которые указаны с ней будут проиндексированы. |
| Sitemap: | Абсолютная ссылка | Здесь указывается ссылка на XML-карту сайта. Если в файле не указать эту директиву, то придется добавлять карту вручную (через Яндекс.Вебмастер или Search Console). |
| Crawl-delay: | Время в секундах (пример: 2.0 — 2 секунды) | Позволяет указать таймаут между посещениями поисковых роботов. Нужна в случае, если эти самые роботы создают дополнительную нагрузку на хостинг. |
| Clean-param: | Динамический параметр | Если на сайте есть параметры вида site.ru/statia?uid=32, где ?uid=32 — параметр, то с помощью этой директивы их можно скрыть. |
В принципе, ничего сложного. Дам дополнительные пояснения по директивам Clean-param (откройте вкладку).
Параметры, как правило, используются на динамических сайтах. Они могут передавать поисковым системам лишнюю информацию — создавать дубли. Чтобы избежать этого, мы должны указать в Robots.txt директиву Clean-param с указанием параметра и ссылки, к которой это параметр применяется.
В нашем примере site.ru/statia?uid=32 — site.ru/statia — ссылка, а все, что после знака вопроса — параметр. Здесь это uid=32. Он динамический, и это значит, что параметр uid может принимать другие значения.
Например, uid=33, uid=34…uid=123434. В теории их может быть сколько угодно, поэтому мы должны закрыть от индексации все параметры uid. Для этого директива должна принять такой вид:
Clean-param: uid /statia # все параметры uid для statia будут закрыты
Более подробно о том, что такое Robots.txt можно узнать из Яндекс.Помощи. Или из этого видеоролика:
Базовый Robots.txt для WordPress
Совсем недавно я приобрел плагин Clearfy Pro для своих проектов. Там очень много разных функций, и одна из них — создание идеального Robots.txt. На самом деле насколько он идеален — я не знаю, вебмастера расходятся во мнениях.
Кто-то предпочитает делать более краткие версии роботса, указывая правила для всех поисковых систем сразу. Другие прописывают отдельные правила для каждого поисковика (в основном для Яндекса и Гугла).
Что из этого правильно — точно сказать не могу. Однако я предлагаю вам ознакомиться с базовой версией Robots.txt для WordPress от Clearfy Pro. Я немного подредактировал ее — указал директиву Sitemap. Удалил директиву Host.
User-agent: * Disallow: /wp-admin Disallow: /wp-includes Disallow: /wp-content/plugins Disallow: /wp-content/cache Disallow: /wp-json/ Disallow: /xmlrpc.php Disallow: /readme.html Disallow: /*? Disallow: /?s= Allow: /*.css Allow: /*.js Sitemap: https://site.ru/sitemap.xml
Не могу сказать, что это лучший вариант для блогов на ВП. Но во всяком случае, он лучше, чем то, что нам предлагает Yoast SEO по умолчанию.
Расширенный Robots.txt для WordPress
Теперь посмотрим на расширенную версию Robots.txt для WordPress. Наверняка вы знаете, что все сайты на WP имеют одинаковую структуру. Одинаковые названия папок, файлов и т.д. позволяют специалистам выявить наиболее приемлемый вариант роботса.
Читайте также: Самые лучшие SEO-оптимизированные шаблоны для WordPress
В этой статье я хочу представить вам свой вариант Robots.txt. Его я использую как для своих сайтов, так и для клиентских. Вы могли видеть такой вариант и на других сайтах, т.к. он обладает некоторой популярностью.
Итак, правильный Robots.txt для WordPress выглядит следующим образом:
User-agent: * # Для всех поисковых систем, кроме Яндекса и Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Disallow: /tag/ # Закрываем метки Disallow: /readme.html # Закрываем бесполезный мануал по установке WordPress (лежит в корне) Disallow: *?replytocom Allow: */uploads User-agent: GoogleBot # Для Гугла Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: *utm= Disallow: *openstat= Disallow: /tag/ # Закрываем метки Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php User-agent: Yandex # Для Яндекса Disallow: /cgi-bin Disallow: /? Disallow: /wp- Disallow: *?s= Disallow: *&s= Disallow: /search/ Disallow: /author/ Disallow: /users/ Disallow: */trackback Disallow: */feed Disallow: */rss Disallow: */embed Disallow: /xmlrpc.php Disallow: /tag/ # Закрываем метки Disallow: /readme.html Disallow: *?replytocom Allow: */uploads Allow: /*/*.js Allow: /*/*.css Allow: /wp-*.png Allow: /wp-*.jpg Allow: /wp-*.jpeg Allow: /wp-*.gif Allow: /wp-admin/admin-ajax.php Clean-Param: utm_source&utm_medium&utm_campaign Clean-Param: openstat Sitemap: https://site.com/sitemap_index.xml # Карта сайта, меняем site.com на нужный адрес.
Важно:Ранее в Robots.txt использовалась директива Host. Она указывала главное зеркало сайта. Теперь это делается при помощи редиректа. Подробнее об этом можно почитать в блоге Яндекса.
Комментарии (текст после #) можно удалить. Указываю Sitemap с https протоколом, т.к. большинство сайтов сейчас используют защищенное соединение. Если у вас нет SSL, то измените протокол на http.
Читайте также: Как правильно настроить WordPress
Обратите внимание на то, что я закрываю метки (теги). Делаю это потому, что они создают большое количество дублей. Это плохо сказывается на SEO, но если вы хотите открыть метки, тогда уберите строчку disallow: /tag/ из файла.
Заключение
В общем-то, вот так выглядит правильный Robots.txt для WordPress. Смело копируйте данные в файл и пользуйтесь. Отмечу, что этот вариант подходит только для стандартных информационных сайтов.
В других ситуациях может потребоваться индивидуальная проработка. На этом все. Спасибо за внимание. Буду благодарен, если вы включите уведомления через колокольчик и подпишитесь на почтовую рассылку. Тут будет круто :).
Если вы нашли ошибку, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Используемые источники:
- https://seogio.ru/robots-txt/
- https://serpstat.com/ru/blog/chto-takoe-robotstxt-i-kak-pravilno-ego-nastroit/
- https://awayne.biz/pravilnyy-robots-txt-dlya-wordpress/

 Настройка плагина Yoast SEO wordpress новая инструкция
Настройка плагина Yoast SEO wordpress новая инструкция Как настроить главное зеркало сайта в Google Search Console и Яндекс.Вебмастер
Как настроить главное зеркало сайта в Google Search Console и Яндекс.Вебмастер Настройка Google XML Sitemaps или успех быстрой индексации вашего сайта
Настройка Google XML Sitemaps или успех быстрой индексации вашего сайта