Содержание
- 1 Что нового в PostgreSQL 10?
- 2 Установка PostgreSQL 10 на Linux Ubuntu Server 16.04
- 3 Базовая настройка PostgreSQL 10 в Linux Ubuntu Server
- 4 Установка PostgreSQL
- 5 Подключение к СУБД
- 6 Подключение PostgreSQL по сети
- 7 Создание ролей
- 8 Создание новой базы данных
- 9 Создание таблицы
- 10 Добавление и удаление данных
- 11 Добавление и удаление столбцов
- 12 Настраиваемые параметры PostgreSQL
- 13 Заключение
Привет! Материал сегодня будет посвящен рассмотрению процесса установки СУБД PostgreSQL 10 на серверную операционную систему Linux Ubuntu Server, а также первоначальной настройки PostgreSQL 10, для того чтобы можно было ее использовать, например, в сети своей организации.
Другими словами, сейчас мы с Вами реализуем сервер баз данных на базе Linux Ubuntu Server и PostgreSQL 10, который будет иметь базовую настройку. Если Вас интересует реализация подобного сервера только на базе операционной системы CentOS 7.1, то можете ознакомиться с материалом «Установка PostgreSQL 9.4 на CentOS 7.1», в нем мы как раз рассматривали данный процесс.

Так как PostgreSQL 10 – это новая версия данной системы управления базами данных, то начать предлагаю с краткого рассмотрения новых возможностей 10 версии.
Примечание!10 версия PostgreSQL была актуальна на момент написания статьи, на текущий момент доступны новые версии.
Содержание
Что нового в PostgreSQL 10?
Начиная с PostgreSQL 10, меняется схема нумерации версий, это вызвано тем, что раньше выходило множество минорных версий (например, 9.x), многие из которых на самом деле вносили значительные изменения не соответствующие минорным, теперь мажорные версии будут нумероваться 10, 11, 12, а минорные 10.1, 10.2, 11.1 и так далее.
Основные нововведения:
- Логическая репликация с использованием публикации и подписки — теперь возможно осуществлять репликацию отдельных таблиц на другие базы, это реализовывается с помощью команд CREATE PUBLICATION и CREATE SUBSCRIPTION;
- Декларативное партиционирование таблиц – в PostgreSQL 10 добавился специальный синтаксис для партиционирования, который позволяет легко создавать и поддерживать таблицы с интервальной или списочной схемой партиционирования;
- Улучшенный параллелизм запросов – другими словами, появилась дополнительная оптимизация запроса, для того чтобы пользователь получал данные быстрей;
- Аутентификация пароля на основе SCRAM-SHA-256 – добавился новый метод аутентификации, который является более безопасным, чем метод с использованием MD5;
- Quorum Commit для синхронной репликации – теперь администратор может указать что, если какое-либо количество реплик подтвердило, что внесено изменение в базу данных, данное изменение можно считать надёжно зафиксированным;
- Значительные общие улучшения производительности;
- Улучшенный мониторинг и контроль.
Более детально обо всех нововведениях можете почитать на официальном сайте – PostgreSQL 10.
Установка PostgreSQL 10 на Linux Ubuntu Server 16.04
Как Вы уже, наверное, поняли рассматривать процесс установки и соответственно настройки PostgreSQL 10 мы будем на примере версии Ubuntu Server 16.04, так как эта версия имеет долгосрочную поддержку и на текущий момент является актуальной среди LTS версий.
 Как установить PostgreSQL на Ubuntu 18.04
Как установить PostgreSQL на Ubuntu 18.04Шаг 1
Установку и настройку PostgreSQL необходимо осуществлять с правами суперпользователя, поэтому давайте сразу переключимся на пользователя root. Для этого вводим sudo -i (или sudo su) и жмем Enter.

Шаг 2
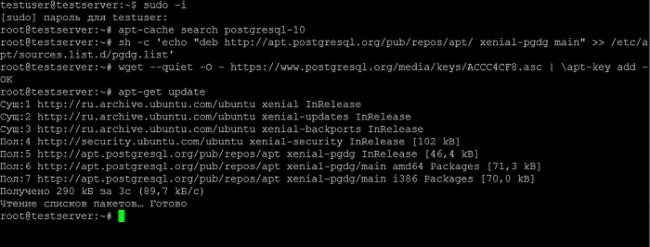
Затем первое, что нам нужно сделать, это проверить есть ли в репозиториях версия PostgreSQL 10. Это можно сделать путем ввода следующей команды.
apt-cache search postgresql-10

Как видим, в Ubuntu Server 16.04 10 версии PostgreSQL нет, поэтому нам нужно подключить необходимый репозиторий, в котором присутствует PostgreSQL 10. Если у Вас более новая версия Ubuntu Server и в стандартных репозиториях есть 10 версия PostgreSQL, то дополнительный репозиторий Вам подключать не нужно, т.е. данный шаг Вы пропускаете.
Для подключения репозитория нам необходимо создать специальный файл с адресом нужного репозитория. Адреса для каждой версии Ubuntu разные, поэтому если у Вас версия Ubuntu не 16.04, то уточнить адрес Вы можете на официальном сайте PostgreSQL на странице загрузке – вот она.
После перехода на страницу выбираете версию Ubuntu, после чего у Вас отобразится адрес нужного репозитория.
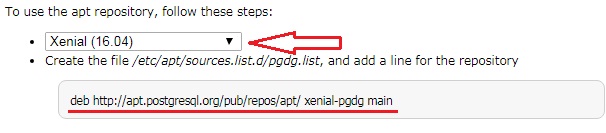
Для упрощения процедуры создания файла давайте напишем скрипт с выводом адреса репозитория, а вывод перенаправим в файл. Для Ubuntu Server 16.04 подключение нужного репозитория будет выглядеть следующим образом.
 ТОП 10 приложений необходимых сразу после установки Ubuntu
ТОП 10 приложений необходимых сразу после установки Ubuntush -c 'echo "deb http://apt.postgresql.org/pub/repos/apt/ xenial-pgdg main" >> /etc/apt/sources.list.d/pgdg.list'
Также нам необходимо импортировать ключ подписи репозитория, для этого вводим команду.
wget --quiet -O - https://www.postgresql.org/media/keys/ACCC4CF8.asc | apt-key add -
Далее обновляем список пакетов.
apt-get update
И еще раз проверяем наличие пакета с PostgreSQL 10.
apt-cache search postgresql-10
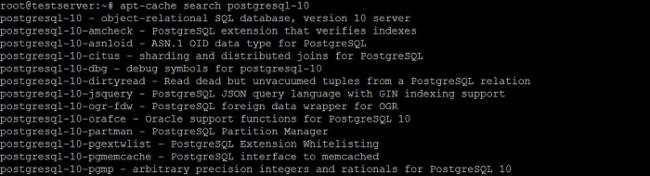
Теперь нужный пакет у нас есть, и мы можем переходить к установке PostgreSQL 10.
Шаг 3
Для установки PostgreSQL 10 пишем следующую команду.
apt-get -y install postgresql-10
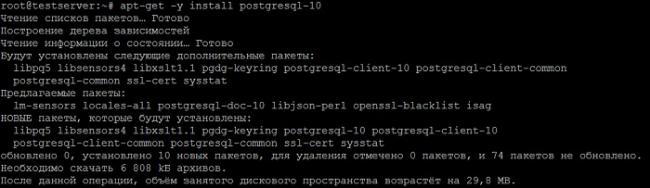
По окончанию процесса установки проверяем, запущен ли сервер PostgreSQL.
 Ubuntu MATE — подробный обзор и установка дистрибутива
Ubuntu MATE — подробный обзор и установка дистрибутиваsystemctl status postgresql
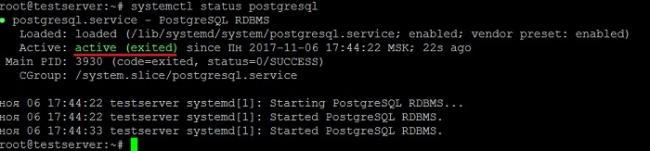
Как видим, PostgreSQL 10 установился и работает.
Базовая настройка PostgreSQL 10 в Linux Ubuntu Server
После установки нам необходимо выполнить базовую настройку PostgreSQL 10, например: создать пользователя, указать какие сетевые интерфейсы будет прослушивать сервер, а также разрешить подключение по сети. Начнем мы с создания пользователя и базы данных.
Создание пользователя и базы данных в PostgreSQL
После установки, к серверу PostgreSQL мы можем подключиться только с помощью системного пользователя postgres, причем без пароля. Для этого переключаемся на пользователя postgres (учетная запись в Ubuntu создана автоматически во время установки PostgreSQL).
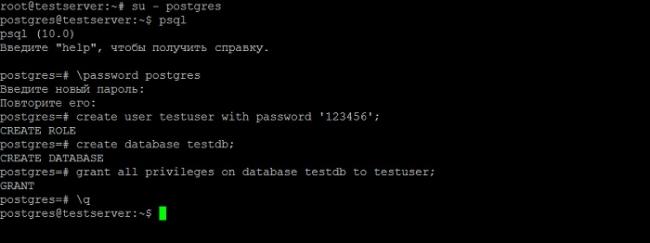
su - postgres
Запускаем psql — это консоль управления PostgreSQL.
psql
Сначала зададим пароль для пользователя postgres.
password postgres
Затем создаем нового пользователя на сервере PostgreSQL, так как работать от имени postgres крайне не рекомендуется.
create user testuser with password '123456';
где, testuser – это имя пользователя, ‘123456’ – это его пароль.
Далее давайте создадим базу данных.
create database testdb;
где, testdb – это имя новой базы данных.
Теперь давайте дадим права на управление БД нашему новому пользователю.
grant all privileges on database testdb to testuser;
Все готово, выходим из консоли.
q
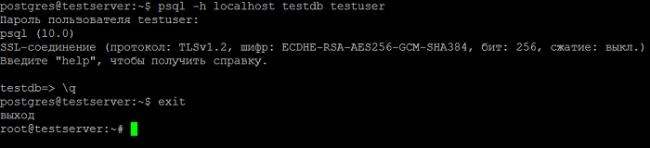
Для проверки, давайте подключимся к PostgreSQL от имени нового пользователя, на предложение о вводе пароля вводим пароль от новой учетной записи.
psql -h localhost testdb testuser
Работает. Для выхода снова набираем q.
q
Для переключения обратно на root вводим exit.
exit
Разрешаем подключение к PostgreSQL по сети
По умолчанию PostgreSQL прослушивает только адрес localhost, поэтому для того чтобы мы могли подключаться по сети, нам нужно указать какие сетевые интерфейсы будет просушивать PostgreSQL. Я для примера укажу, что прослушивать нужно все доступные интерфейсы. Если у Вас несколько сетевых интерфейсов, и Вы хотите, чтобы PostgreSQL использовал только один конкретный, то Вы его можете указать именно здесь.
Для этого открываем файл postgresql.conf, например редактором nano.
nano /etc/postgresql/10/main/postgresql.conf
Находим следующую строку.
#listen_addresses = 'localhost'
и заменяем на (вместо звездочки Вы в случае необходимости указываете IP адрес нужного интерфейса).
listen_addresses = '*'
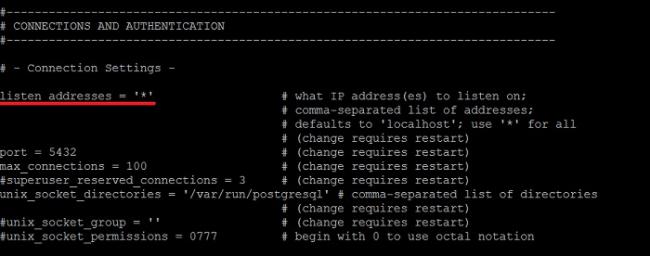
Сохраняем изменения сочетанием клавиш CTRL+O и подтверждаем нажатием Enter, затем просто закрываем редактор nano сочетанием клавиш CTRL+X.
Теперь давайте разрешим подключение из сети 10.0.2.0/24 с методом аутентификации md5. Для этого открываем файл pg_hba.conf
nano /etc/postgresql/10/main/pg_hba.conf
Ищем вот такие строки.

И вносим следующие изменения (если IPv6 Вы не будете использовать, то можете закомментировать соответствующие строки знаком #).
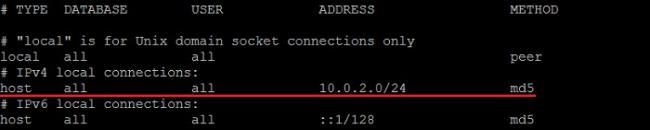
Где, 10.0.2.0/24 адрес сети, из которой будет происходить подключение к текущему серверу PostgreSQL. Сохраняем изменения сочетанием клавиш CTRL+O, подтверждаем нажатием Enter и закрываем редактор nano сочетанием клавиш CTRL+X.
Перезапускаем PostgreSQL
systemctl restart postgresql
Все, установка и настройка PostgreSQL закончена, можете подключаться к серверу из сети клиентским приложением. Пока, надеюсь, материал был Вам полезен!
PostgreSQL – кроссплатформенная СУБД с расширенной функциональностью, и открытым исходным кодом. Она совместима со многими операционными системами. Чтобы установить PostgreSQL на Ubuntu, потребуется уже развернутая операционная система, пользователь с привилегиями sudo и базовый файрвол.
В статье рассмотрим установку, настройку и удаление на Ubuntu PostgreSQL версии 11.1.
Установка PostgreSQL
Установить PostgreSQL можно непосредственно из репозитория Ubuntu. По умолчанию его пакеты уже находятся в операционной системе. Перед установкой нужно сначала выполнить их обновление командой:
sudo apt update
Далее следует установка самого ПО совместно с пакетом contrib, в котором содержаться дополнительные инструменты и утилиты:
sudo apt install postgresql postgresql-contrib
Установка PostgreSQL на Ubuntu 18.04 завершена.
Подключение к СУБД
В процессе инсталляции, программа автоматически создает пользователя базы данных с правами администратора – postgres. Войти в СУБД на данный момент можно только через эту учетную запись. Следует добавить созданного пользователя в группу sudo:
usermod -a -G sudo postgres
Установить для него пароль:
passwd postgres
Выполнить запуск оболочки программы, можно переключившись на сессию учетной записи. Для этого используется команда:
sudo su - postgres psql
Ее можно также запустить, не переключая сессию от имени postgres:
sudo -u postgres psql
Для выхода из командной строки нужно ввести команду:
q
Подключение PostgreSQL по сети
По умолчанию эта СУБД слушает только localhost (компьютер, на который устанавливается база данных). Чтобы подключиться к ней по сети нужно указать, какие сетевые интерфейсы ей следует прослушивать.
Для этого нужно открыть файл postgresql.conf:
nano /etc/postgresql/10/main/postgresql .conf
Найти строчку:
#listen_addresses = ’localhost’
Здесь необходимо произвести замену параметра «’localhost’» в зависимости от того, сколько интерфейсов нужно прослушивать. Например, если нужна прослушка всего перечня доступных интерфейсов, то вписываем параметры «000.00.0.0»:
listen_address = ’000.00.0.0’
Если же требуется прослушивать конкретный IP, то нужно вписать именно этот адрес (например — 194.61.0.6):
listen_address = ’194.61.0.6’
Теперь нужно создать правила авторизации для безопасного подключения. Для этого добавить строку в файле /etc/postgresql/10/main/pg_hba.conf:
host all all 192.168.0.10/32 password
Где вместо 192.168.0.10/32 вписывается адрес (с маской подсети), откуда идет подключение к базе данных.
Выполняется сохранение и перезапуск PostgreSQL:
systemctl restart postgresql
На этом настройка PostgreSQL на Ubuntu закончена.
Создание ролей
Часто для работы с БД возникает необходимость нескольких учетных записей.
Чтобы создать нового пользователя, используется команда createuser. Для работы в интерактивном режиме применяется ключ –interactive. При этом будет запрошено имя новой роли и права суперпользователя.
После того, как выполнен вход в аккаунт под пользователем postgres, нужно создать новую роль:
createuser --interactive
Если не нужно переключать аккаунты, то предыдущую команду нужно записать так:
sudo -u postgres createuser --interactive
После этого выбирается имя новой учетной записи и задаются такие параметры, как привилегии суперпользователя, разрешение на создание БД и возможность создавать роли:
Enter name of role to add: cloud Shall the new role be a superuser? (y/n) n Shall the new role be a allowed to create databases? (y/n) y Shall the new role be a allowed to create more new roles? n
Если понадобится сделать больше настроек, то с помощью следующей команды можно просмотреть все ключи:
;lmm man createuser
Создание новой базы данных
При создании базы данных, важно не забыть, что она имеет такое же название, как и пользователь под которым происходит авторизация. Ранее была создана роль testuser, значит такое же имя нужно дать и для базы данных. Для этого после авторизации под пользователем postgres, следует ввести команду:
createdb testuser
Если не требуется переключение аккаунта, то вводится команда:
$ sudo -u postgres createdb testuser
Создание таблицы
Базовая команда для создания таблицы выглядит так:
CREATE TABLE table_name ( column_name1 col_type (field_lenght) column_constraints, column_name2 col_type (field_lenght), column_name3 col_type (field_lenght) );
Изначально присваивается имя таблице, потом дается название столбцам, указывается их тип, и длина значений.
Посмотреть готовую таблицу можно с помощью команды:
d
Добавление и удаление данных
Чтобы добавить данные в таблицу применяется команда INSERTINTO. Это можно сделать двумя способами.
Первый, короткий вариант:
INSERT INTO название_таблицы VALUES (1, ’Milk’, 9.99);
Здесь главное не забывать про последовательность столбцов, для правильного введения значения.
В другом способе в команде указываются столбцы:
INSERT INTO название_таблицы (product_no, name, price) VALUES (1, ’Cheese’ 9.99); INSERT INTO название_таблицы (name, price, product_no) VALUES (1, ’Cheese’ 9.99? 1);
Чтобы удалить записи, нужно использовать следующую команду:
DELETE FROM название_таблицы WHERE название_столбца = значение;
После выполнения этой команды, строки в которых будут заданы значения столбцов, удалятся:
DELETE FROM products WHERE price = 10;
Если данные значений не нужно указывать, тогда следует удалить все строки таблицы:
DELETE FROM products;
Добавление и удаление столбцов
При добавлении столбцов следует использовать команду:
ALTER TABLE название_таблицы ADD название_нового_столбца тип_столбца;
По завершении команды будет создан новый столбец с заданным названием.
Чтобы его удалить, следует выполнить команду:
ALTER TABLE название_таблицы DROP название_существующего столбца;
Теперь можно приступить к работе с базой данных. Для подключения к ней нужно запустить psql с параметрами:
- Хост–hlocalhost (подключение к локальной БД);
- Имя базы данныхtestuser;
- Имя пользователяusername.
Общий вид команды:
psql -h localhost testuser_db username
Теперь установка и настройка PostgreSQL на Ubuntu завершена. Можно полноценно взаимодействовать с СУБД: создавать таблицы, делать выборки и хранить информацию.
Чтобы удалить PostgreSQL из Ubuntu, необходимо выполнить последовательность определенных команд:
sudo apt-get --purge remove pgadmin3 sudo apt-get --purge remove postgresgl* sudo rm -rf /etc/postgresgl sudo rm -rf /etc/postgresgl-common sudo rm -rf /var/lib/postgresgl sudo userdel -r postgres sudo groupdel postgres
Теперь СУБД PostgreSQL удалена из Ubuntu.
Автор оригинала: Ibrar Ahmed
- Перевод
 По умолчанию конфигурация PostgreSQL не настроена для рабочей нагрузки. Значения по умолчанию установлены для обеспечения работоспособности PostgreSQL везде с наименьшим количеством ресурсов. Имеются настройки по умолчанию для всех параметров базы данных. Главной обязанностью администратора базы данных или разработчика является настройка PostgreSQL в соответствии с нагрузкой их системы. В этом блоге мы изложим основные рекомендации по настройке параметров базы данных PostgreSQL для повышения производительности базы данных в соответствии с рабочей нагрузкой. Имейте в виду, что, хотя оптимизация конфигурации сервера PostgreSQL повышает производительность, разработчик базы данных также должен быть внимательным при написании запросов. Если запросы выполняют полное сканирование таблицы, где можно использовать индекс, или выполнют тяжелые объединения или дорогостоящие операции агрегирования, тогда система все равно может работать плохо, даже если параметры базы данных настроены корректно. При написании запросов к базе данных важно обращать внимание на производительность. Тем не менее, параметры базы данных тоже очень важны, поэтому давайте посмотрим на восемь, которые имеют наибольший потенциал для повышения производительности
По умолчанию конфигурация PostgreSQL не настроена для рабочей нагрузки. Значения по умолчанию установлены для обеспечения работоспособности PostgreSQL везде с наименьшим количеством ресурсов. Имеются настройки по умолчанию для всех параметров базы данных. Главной обязанностью администратора базы данных или разработчика является настройка PostgreSQL в соответствии с нагрузкой их системы. В этом блоге мы изложим основные рекомендации по настройке параметров базы данных PostgreSQL для повышения производительности базы данных в соответствии с рабочей нагрузкой. Имейте в виду, что, хотя оптимизация конфигурации сервера PostgreSQL повышает производительность, разработчик базы данных также должен быть внимательным при написании запросов. Если запросы выполняют полное сканирование таблицы, где можно использовать индекс, или выполнют тяжелые объединения или дорогостоящие операции агрегирования, тогда система все равно может работать плохо, даже если параметры базы данных настроены корректно. При написании запросов к базе данных важно обращать внимание на производительность. Тем не менее, параметры базы данных тоже очень важны, поэтому давайте посмотрим на восемь, которые имеют наибольший потенциал для повышения производительности
Настраиваемые параметры PostgreSQL
PostgreSQL использует свой собственный буфер, а также использует буферизованный IO ядра. Это означает, что данные хранятся в памяти дважды, сначала в буфере PostgreSQL, а затем в буфере ядра. В отличие от других баз данных, PostgreSQL не обеспечивает прямой ввод-вывод. Это называется двойной буферизацией. Буфер PostgreSQL называется shared_buffer, который является наиболее эффективным настраиваемым параметром для большинства операционных систем. Этот параметр устанавливает, сколько выделенной памяти будет использоваться PostgreSQL для кеширования. Значение по умолчанию для shared_buffer установлено очень низким, и вы не получите большой выгоды от него. Сделано это потому, что некоторые машины и операционные системы не поддерживают более высокие значения. Но в большинстве современных машин вам необходимо увеличить это значение для оптимальной производительности. Рекомендуемое значение составляет 25% от общего объема оперативной памяти компьютера. Вам следует попробовать некоторые более низкие и более высокие значения, потому что в некоторых случаях можно получить хорошую производительность с настройкой более 25%. Но реальная конфигурация зависит от вашей машины и рабочего набора данных. Если ваш рабочий набор данных может легко поместиться в вашу оперативную память, вы можете увеличить значение shared_buffer, чтобы оно содержало всю вашу базу данных и чтобы весь рабочий набор данных мог находиться в кеше. Тем не менее, вы, очевидно, не хотите резервировать всю оперативную память для PostgreSQL. Замечено, что в производственных средах большое значение для shared_buffer действительно дает хорошую производительность, хотя для достижения правильного баланса всегда следует проводить тесты.Проверка значения shared_buffer
testdb=# SHOW shared_buffers; shared_buffers ---------------- 128MB (1 row)Примечание: Будьте осторожны, так как некоторые ядра не поддерживают большее значение, особенно в Windows.
wal_buffers
PostgreSQL сначала записывает записи в WAL (журнал предзаписи) в буферы, а затем эти буферы сбрасываются на диск. Размер буфера по умолчанию, определенный wal_buffers, составляет 16 МБ. Но если у вас много одновременных подключений, то более высокое значение может повысить производительность.
effective_cache_size
effective_cache_size предоставляет оценку памяти, доступной для кэширования диска. Это всего лишь ориентир, а не точный объем выделенной памяти или кеша. Он не выделяет фактическую память, но сообщает оптимизатору объем кеша, доступный в ядре. Если значение этого параметра установлено слишком низким, планировщик запросов может принять решение не использовать некоторые индексы, даже если они будут полезны. Поэтому установка большого значения всегда имеет смысл.
work_mem
Эта настройка используется для сложной сортировки. Если вам нужно выполнить сложную сортировку, увеличьте значение work_mem для получения хороших результатов. Сортировка в памяти происходит намного быстрее, чем сортировка данных на диске. Установка очень высокого значения может стать причиной узкого места в памяти для вашей среды, поскольку этот параметр относится к операции сортировки пользователя. Поэтому, если у вас много пользователей, пытающихся выполнить операции сортировки, тогда система выделит:
work_mem * total sort operationsдля всех пользователей. Установка этого параметра глобально может привести к очень высокому использованию памяти. Поэтому настоятельно рекомендуется изменить его на уровне сеанса.work_mem = 2MB
testdb=# SET work_mem TO "2MB"; testdb=# EXPLAIN SELECT * FROM bar ORDER BY bar.b; QUERY PLAN ----------------------------------------------------------------------------------- Gather Merge (cost=509181.84..1706542.14 rows=10000116 width=24) Workers Planned: 4 -> Sort (cost=508181.79..514431.86 rows=2500029 width=24) Sort Key: b -> Parallel Seq Scan on bar (cost=0.00..88695.29 rows=2500029 width=24) (5 rows)Первоначальный узел сортировки запроса оценивается в 514431,86. Стоимость — это произвольная вычисляемая единица. Для приведенного выше запроса у нас work_mem всего 2 МБ. В целях тестирования давайте увеличим это значение до 256 МБ и посмотрим, повлияет ли это на стоимость.work_mem = 256MB
testdb=# SET work_mem TO "256MB"; testdb=# EXPLAIN SELECT * FROM bar ORDER BY bar.b; QUERY PLAN ----------------------------------------------------------------------------------- Gather Merge (cost=355367.34..1552727.64 rows=10000116 width=24) Workers Planned: 4 -> Sort (cost=354367.29..360617.36 rows=2500029 width=24) Sort Key: b -> Parallel Seq Scan on bar (cost=0.00..88695.29 rows=2500029 width=24)Стоимость запроса снижена с 514431,86 до 360617,36, то есть уменьшилась на 30%.
maintenance_work_mem
maintenance_work_mem — это параметр памяти, используемый для задач обслуживания. Значение по умолчанию составляет 64 МБ. Установка большого значения помогает в таких задачах, как VACUUM, RESTORE, CREATE INDEX, ADD FOREIGN KEY и ALTER TABLE.maintenance_work_mem = 10MB
postgres=# CHECKPOINT; postgres=# SET maintenance_work_mem to '10MB'; postgres=# CREATE INDEX foo_idx ON foo (c); CREATE INDEX Time: 170091.371 ms (02:50.091)maintenance_work_mem = 256MB
postgres=# CHECKPOINT; postgres=# set maintenance_work_mem to '256MB'; postgres=# CREATE INDEX foo_idx ON foo (c); CREATE INDEX Time: 111274.903 ms (01:51.275)Время создания индекса составляет 170091,371 мс, если для параметра maintenance_work_mem установлено значение только 10 МБ, но оно уменьшается до 111274,903 мс, когда мы увеличиваем значение параметра maintenance_work_mem до 256 МБ.
synchronous_commit
Используется для обеспечения того, что фиксация транзакции будет ожидать записи WAL на диск, прежде чем вернуть клиенту статус успешного завершения. Это компромисс между производительностью и надежностью. Если ваше приложение разработано таким образом, что производительность важнее надежности, отключите synchronous_commit. В этом случае транзакция фиксируется очень быстро, потому что она не будет ожидать сброса файла WAL, но надежность будет поставлена под угрозу. В случае сбоя сервера данные могут быть потеряны, даже если клиент получил сообщение об успешном завершении фиксации транзакции.
checkpoint_timeout, checkpoint_completion_target
PostgreSQL записывает изменения в WAL. Процесс контрольной точки сбрасывает данные в файлы. Это действие выполняется, когда возникает контрольная точка (CHECKPOINT). Это дорогостоящая операция и может вызвать огромное количество операций IO. Весь этот процесс включает в себя дорогостоящие операции чтения/записи на диск. Пользователи могут всегда запустить задание контрольной точки (CHECKPOINT), когда это необходимо, или автоматизировать запуск с помощью параметров checkpoint_timeout и checkpoint_completion_target. Параметр checkpoint_timeout используется для установки времени между контрольными точками WAL. Установка слишком низкого значения уменьшает время восстановления после сбоя, поскольку на диск записывается больше данных, но это также снижает производительность, поскольку каждая контрольная точка в конечном итоге потребляет ценные системные ресурсы. checkpoint_completion_target — это доля времени между контрольными точками для завершения контрольной точки. Высокая частота контрольных точек может повлиять на производительность. Для плавного выполнения задания контрольной точки, checkpoint_timeout должен иметь низкое значение. В противном случае ОС будет накапливать все грязные страницы до тех пор, пока соотношение не будет соблюдено, а затем производить большой сброс.
Заключение
Есть больше параметров, которые можно настроить, чтобы получить лучшую производительность, но они оказывают меньшее влияние, чем те, которые выделены здесь. В конце концов, мы всегда должны помнить, что не все параметры актуальны для всех типов приложений. Некоторые приложения работают лучше, при настройке параметров, а некоторые нет. Настройка параметров базы данных PostgreSQL должна выполняться в соответствии с конкретными потребностями приложения и операционной системы, в которой оно работает.Используемые источники:
- https://info-comp.ru/sisadminst/598-install-postgresql-10-on-ubuntu-server.html
- https://eternalhost.net/base/vps-vds/ustanovka-postgresql-ubuntu
- https://habr.com/post/458952/

 Настройка Ubuntu 18.04 после установки
Настройка Ubuntu 18.04 после установки Настройка и оптимизация Ubuntu после установки
Настройка и оптимизация Ubuntu после установки Идеальная Ubuntu — настройка от А до Я
Идеальная Ubuntu — настройка от А до Я 14 советов, что нужно сделать после установки Ubuntu 16.10
14 советов, что нужно сделать после установки Ubuntu 16.10