PostgreSQL — достаточно современная и популярная СУБД в мире. Её не обошла и фирма 1С, выбрав в качестве одной из поддерживаемых для работы СУБД. Рассмотрим инструкцию по установке PostgreSQL и её первоначальной настройки для 1С 8.3 под ОС Windows.
![]()
PostgreSQL — бесплатная программа, это является одним из решающих факторов по выбору данной СУБД.
Для установки сервера нам понадобится два архива — сервера 1С предприятия (х86-64) и дистрибутив PostgreSQL. В нашем примере платформа версии 8.3.4, а СУБД 9.1.2. Их лучше взять из официальных источников 1С — диска или сайта ИТС.
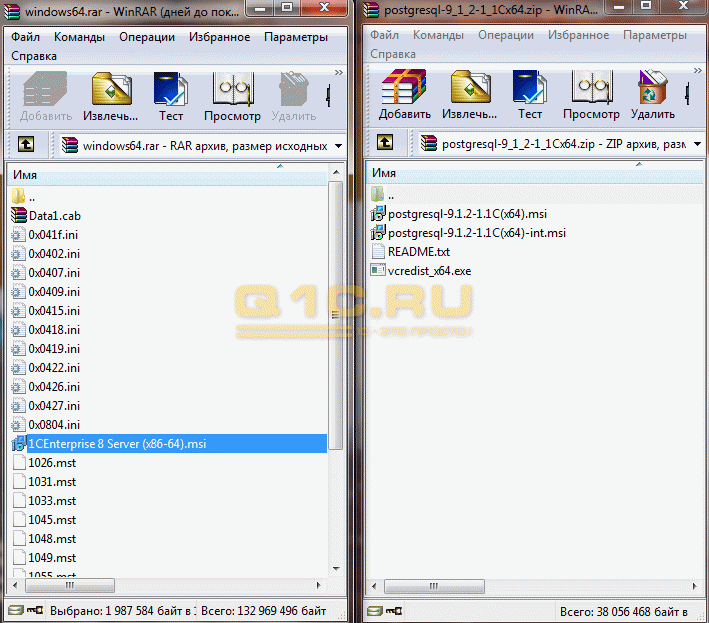
Установка и настройка сервера 1С Предприятие
Первым делом установим сервер 1C предприятия 8.3 (или 8.2). Для этого запустим файл setup.exe из архива. Установка мало чем отличается от обычной установки клиентского приложения, за исключением некоторых особенностей:
1. Не забудьте выбрать в компонентах нужные пункты:
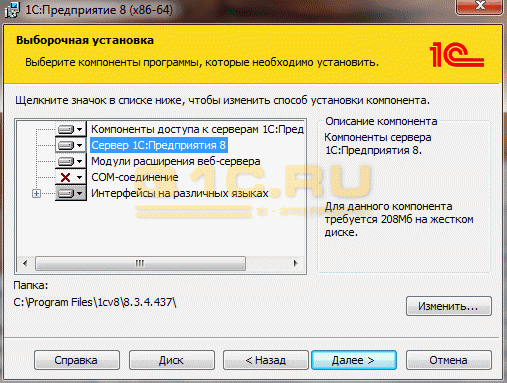
2. Указать, от чьего имени будет запускаться приложение. Рекомендуется создавать нового пользователя «USR1Cv8». У этого пользователя должны быть установлены нужные права:
Получите 267 видеоуроков по 1С бесплатно:
 Установка и первичная настройка PostgreSQL на Ubuntu 18.04
Установка и первичная настройка PostgreSQL на Ubuntu 18.04К сожалению, мы физически не можем проконсультировать бесплатно всех желающих, но наша команда будет рада оказать услуги по внедрению и обслуживанию 1С. Более подробно о наших услугах можно узнать на странице Услуги 1С или просто позвоните по телефону +7 (499) 350 29 00. Мы работаем в Москве и области.
Оцените статью, пожалуйста!
28 января 2017 ВКTwFb
В этой инструкции мы расскажем (и покажем) как настроить связку 1С:Предприятие 8.3 и PostgreSQL 9.4.2 с момента установки обоих сервисов, вплоть до создания информационной базы. Про тюнинг данной связки можно прочитать в другой нашей статье.
Этапы, которые нам предстоит пройти:
- Установка Сервера 1С:Предприятие (64-bit) для Windows
- Установка PostgreSQL 9.4.2-1.1С
- Создание Информационной базы данных.
Этап 0. Вводные данные.
Имя сервера — 1CServer Имя учётной записи сервера — Администратор Пароль учётной записи — 123456Ab
Имя учётной записи 1С на сервере — USR1CV8Пароль учётной записи 1С на сервере — 123456Cd
Имя учётной записи PostgreSQL на сервере — Пароль учётной записи PostgreSQL на сервере — Имя суперюзера PostgreSQL — postgres Пароль суперюзера PostgreSQL — 1234
Имя тестовой базы данных — testdb
 Настройка параметров PostgreSQL для оптимизации производительности
Настройка параметров PostgreSQL для оптимизации производительностиЭтап 1. Установка Сервера 1С:Предприятие (64-bit) для Windows
- Заходим на сайт users.v8.1c.ru.
- Переходим в раздел Технологические дистрибутивы > Технологическая платформа 8.3 > 8.3.8.2197 (не очень важно, но подальше от последней) > Cервер 1С:Предприятия (64-bit) для Windows > Скачать дистрибутив.
- Загружаем архив windows64.rar. Распаковываем его.
- Начинаем установку через setup.exe.
- Просто проходим через каждый пункт до пункта «Установить сервер 1С:Предприятие 8 как сервис…». В данном пункте галочка должна стоять, радио-кнопку надо переключить в положение «Создать пользователя USR1CV8». Пароль может быть любым, но отвечающим политикам безопасности сервера Windows. В нашем примере это 123456Cd.
- Дальше опять никаких откровений — просто везде нажимаем «Далее». На этом мы пока завершаем работу с Сервером 1С:Предприятие и переходим к установке PostgreSQL.
Этап 2. Установка PostgreSQL и pgAdmin.
- Невероятных ссылок, откуда скачать PostgreSQL не будет — это наш любимый сайт https://releases.1c.ru, раздел «Технологические дистрибутивы». Скачиваем, ставим. Не забываем установить MICROSOFT VISUAL C++ 2010 RUNTIME LIBRARIES WITH SERVICE PACK 1, который идёт в архиве с дистрибутивом. Сами попались на это: не установили, испытали много боли.
- Ставим всё на «Далее», кроме следующих моментов. Устанавливаем, как сервис (галочка) и задаём параметры для учётной записи Windows, не PostgreSQL (учётка, от имени которой будет работать служба). В нашем случае это postgres и 123456Ef. Пароль должен отвечать политикам безопасности сервера Windows.
- Инициализируем кластер базы данных (галочка). А вот здесь задаём параметры учётной записи для PostgreSQL! Важно: у Вас должна быть запущена служба «Secondary Logon» (или на локализированных ОС: «Вторичный вход в систему»). Кодировка UTF8 — это тоже важно! На этом этапе Имя суперюзера postgres, а пароль 1234.
- Дальше ничего интересного. Далее…
- pgAdmin в этой сборке староват. Идём на https://www.postgresql.org/ftp/pgadmin3/release/. На момент написания статьи самая свежая версия 1.22.1. Качаем её, ставим. Заходим.
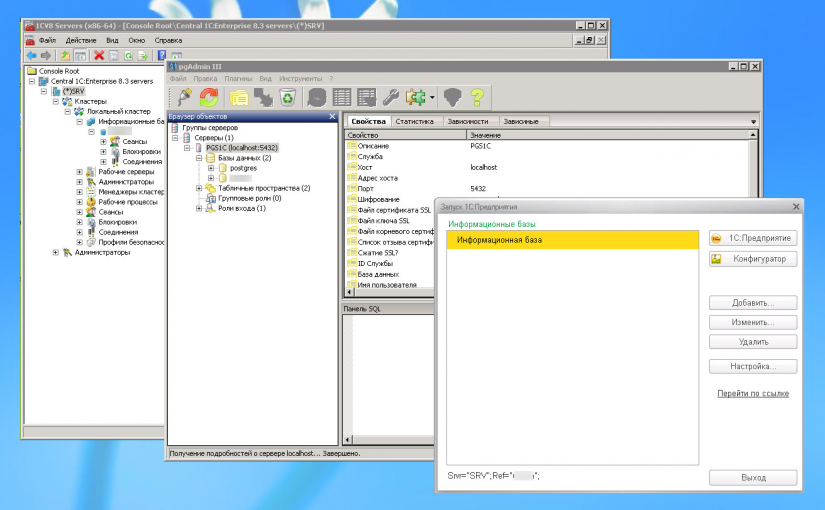
Этап 3. Создание информационной базы 1С.
- Перед выполнением следующих операций, отключите IPv6 на Вашем сетевом интерфейсе: Центр управления сетями и общим доступом > Подключение по локальной сети > Свойства > Снимите галочку с Протокол Интернета версии 6 (TCP/IPv6).
- Запускаем клиентское 1С:Предприятие и добавляем новую базу данных.
- Создание новой информационной базы > Создание информационной базы без конфигурации (для примера, у Вас может быть любая конфигурация) > На сервере 1С:Предприятие >
- Заполняем все поля в соответствии с нашим примером (Этап 0): Кластер серверов 1С:Предприятие: 1CServer Имя информационной базы в кластере: testbd Защищённое соединение: Выключено Тип СУБД: PostgreSQL Сервер баз данных: 1CServer Имя базы данных: testbd Пользователь базы данных: postgres Пароль пользователя: 1234
- Далее, далее. Запускаем созданную базу в режиме предприятия — всё работает!
Ещё раз напоминаем, что PostgreSQL можно неплохо разогнать. Подробности в нашей статье. И не забудьте про резервное копирование баз данных 1С! Если с базой данных возникли какие-то проблемы, возможно, Вам поможет внутреннее или внешнее тестирование. Базы данных 1С можно публиковать на веб-серверах!
 PostgreSQL приобретает все большую популярность как СУБД для использования в связке с 1С:Предприятие. При этом одним из самых частых нареканий является низкая производительность этого решения. Во многом это связано с тем, что настройки PostgreSQL по умолчанию не являются оптимальными, а обеспечивают запуск и работу СУБД на минимальной конфигурации. Поэтому имеет смысл потратить некоторое количество времени на оптимизацию производительности сервера, тем более что это не очень сложно.
PostgreSQL приобретает все большую популярность как СУБД для использования в связке с 1С:Предприятие. При этом одним из самых частых нареканий является низкая производительность этого решения. Во многом это связано с тем, что настройки PostgreSQL по умолчанию не являются оптимальными, а обеспечивают запуск и работу СУБД на минимальной конфигурации. Поэтому имеет смысл потратить некоторое количество времени на оптимизацию производительности сервера, тем более что это не очень сложно.
Существуют разные рекомендации по оптимизации PostgreSQL для совместной работы с 1С, мы будем опираться на официальные рекомендации, изложенные на ИТС, также можно использовать онлайн-калькулятор для быстрого расчета некоторых параметров. Если данные калькулятора и рекомендации 1С будут расходиться — то предпочтение будет отдано рекомендациям 1С.
Для тестирования мы использовали систему:
- CPU — Core i5-4670 — 3.4/3.8 ГГц
- RAM — 32 ГБ DDR3
- Системный диск — SSD WD Green 120 ГБ
- Диск для данных — 2 х SSD Samsung 860 EVO 250 ГБ — RAID1
- СУБД — PostgresPro 11.6
- Платформа — 8.3.16.1148
- ОС — Debian 10 x64
Прежде всего выполним тестирование с параметрами по умолчанию:
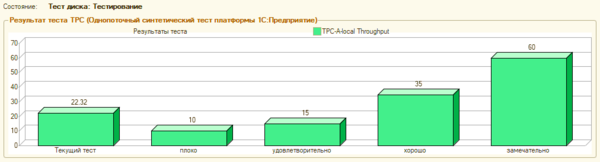 Полученный результат — 22,32 по Гилеву высоким не назовешь, для субъективного контроля мы использовали конфигурацию Розница 2.2 с базой реального торгового предприятия объемом в 8 ГБ, в целом работу можно было признать удовлетворительной, но местами наблюдалась некоторая «задумчивость», особенно при открытии динамических списков.
Полученный результат — 22,32 по Гилеву высоким не назовешь, для субъективного контроля мы использовали конфигурацию Розница 2.2 с базой реального торгового предприятия объемом в 8 ГБ, в целом работу можно было признать удовлетворительной, но местами наблюдалась некоторая «задумчивость», особенно при открытии динамических списков.
Перейдем к оптимизации. Все изменения следует вносить в файл postgesql.conf, который располагается в Linuх для сборки от 1С по пути /etc/postgres/1x/main, а для сборки от PostgresPro в /var/lib/pgpro/1c-1x/data. В Windows данный файл располагается в каталоге данных, по умолчанию это C:Program FilesPostgreSQL 1C1хdata. Все параметры указаны в порядке их следования в конфигурационном файла.
Одним из основных параметров, используемых при расчетах, является объем оперативной памяти. При этом следует использовать то значение, которое вы готовы выделить серверу СУБД, за вычетом ОЗУ используемой ОС и другими службами, скажем, сервером 1С. В нашем случае будет использоваться значение в 24 ГБ.
Затем рассчитаем значения отдельных параметров с помощью калькулятора, для чего укажем ОС и версию Postgres, тип накопителя, количество доступной памяти и количество ядер процессора. В поле DB Type указываем Data Warehouses, количество соединений можем проигнорировать, так как вычисляемый результат будет значительно расходиться с рекомендациями 1С.
 Как установить PostgreSQL на Ubuntu 18.04
Как установить PostgreSQL на Ubuntu 18.04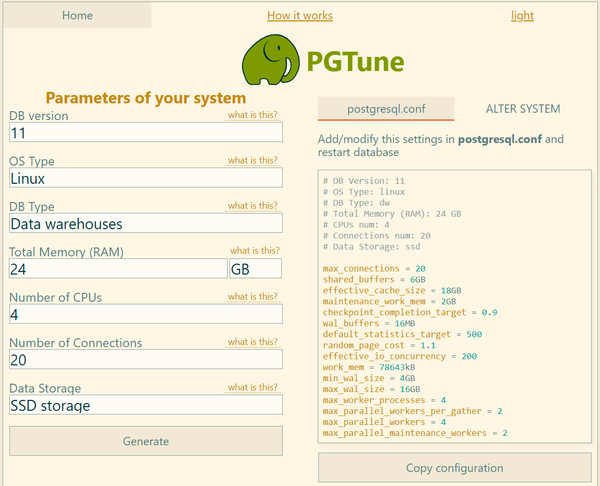 Теперь можно приступать к редактированию файла конфигурации. Многие значения в нем закомментированы и содержат значения по умолчанию, при изменении таких параметров данные строки следует раскомментировать.
Теперь можно приступать к редактированию файла конфигурации. Многие значения в нем закомментированы и содержат значения по умолчанию, при изменении таких параметров данные строки следует раскомментировать.
max_connections = 500..1000Максимальное число соединений, 1С рекомендует указанные выше значения, мы установили 1000.
shared_buffers = RAM/4Объем памяти для совместного кеша страниц, разделяется между всеми процессами Postgres, рекомендуемое значение — четверть доступного объема памяти, в нашем случае 6 ГБ.
temp_buffers = 256MBВерхний лимит для временных таблиц в каждой сессии, рекомендуется фиксированное значение.
work_mem = RAM/32..64Указывает объем памяти, который может быть использован для запроса прежде, чем будут задействованы временные файлы на диске. Применяется для каждого соединения и каждой операции, поэтому итоговый объем используемой памяти может существенно превосходить указанное значение. Это один из тех параметров, вычисляемое значение которого калькулятором существенно отличается от рекомендаций 1С. Для объема памяти в 24 ГБ рекомендуемыми значениями будут 375 — 750 МБ, мы выбрали 512 МБ.
maintenance_work_mem = RAM/16..32 или work_mem * 4Объем памяти для обслуживающих задач (автовакуум, реиндексация и т.д.), указываем рекомендованный калькулятором объем, в нашем случае 2 ГБ.
max_files_per_process = 1000Максимальное количество открытых файлов на один процесс, в сборке от PostgresPro для Linux это значение по умолчанию.
bgwriter_delay = 20msbgwriter_lru_maxpages = 400bgwriter_lru_multiplier = 4.0Параметры процесса фоновой записи, который отвечает за синхронизацию страниц в shared_buffers с диском.
effective_io_concurrency = 2 для RAID, 200 для SSD, 500..1000 для NVMeДопустимое число одновременных операций ввода/вывода. Для жестких дисков указывается по количеству шпинделей, для массивов RAID5/6 следует исключить диски четности. Для SATA SSD это значение рекомендуется указывать равным 200, а для быстрых NVMe дисков его можно увеличить до 500-1000. При этом следует понимать, что высокие значения в сочетании с медленными дисками сделают обратный эффект, поэтому подходите к этой настройке грамотно.
Важно! Параметр effective_io_concurrency настраивается только в среде Linux, в Windows системах его значение должно быть равно нулю.
max_worker_processes = 4max_parallel_workers_per_gather = 2max_parallel_workers = 4max_parallel_maintenance_workers = 2Настройки фоновых рабочих процессов, выбираются исходя из количества процессорных ядер, берем значения из калькулятора. Выше указаны настройки для четырехъядерного СРU.
fsync = onЗаставляет сервер добиваться физической записи изменений на диск. Выключение данной опции хотя и позволяет повысить производительность, но значительно увеличивает риск неисправимой порчи данных при внезапном выключении питания.
synchronous_commit = offАльтернатива отключению fsync, позволяет серверу не ждать сохранения данных на диске, прежде чем сообщить клиенту об успешном завершении операции. Позволяет достаточно безопасно повысить производительность работы. В случае внезапного выключения питания могут быть потеряны несколько последних транзакций, но сама база останется в рабочем состоянии, также, как и при штатной отмене потерянных транзакций.
wal_buffers = 16MBЗадает размер буферов журнала предзаписи (WAL, он же журнал транзакций), если оставить эту настройку без изменений, то сервер будет автоматически устанавливать это значение в 1/32 от shared_buffers, но не менее 64 КБ и не более размера одного сегмента WAL в 16 МБ.
commit_delay = 1000commit_siblings = 5Указывает задержку в мс перед записью транзакций на диск при числе открытых транзакций, указанных во второй опции. Имеет смысл при количестве транзакций более 1000 в секунду, на меньших значениях эффекта не имеет.
min_wal_size = 512MB..4G max_wal_size = 2..4 * min_wal_sizeМинимальный и максимальный размер файлов журнала предзаписи. Указываем значения из калькулятора, в нашем случае это 4 ГБ и 16 ГБ.
checkpoint_completion_target = 0.5..0.9Скорость записи изменений на диск, рассчитывается как время между точками сохранения транзакций (чекпойнты) умноженное на данный показатель, позволяет растянуть процесс записи по времени и тем самым снизить одномоментную нагрузку на диски. В нашем случае использовано рекомендованное калькулятором максимальное значение 0,9.
seq_page_cost = 1.0Стоимость последовательного чтения с диска, является относительным числом, вокруг которого определяются все остальные переменные стоимости, данное значение является значением по умолчанию.
random_page_cost = 1.5..2.0 для RAID, 1.1..1.3 для SSDСтоимость случайного чтения с диска, чем ниже это число, тем более вероятно использование сканирования по индексу, нежели полное считывание таблицы, однако не следует указывать слишком низких, не соответствующих реальной производительности дисковой подсистемы, значений, иначе вы можете получить обратный эффект, когда производительность упрется в медленный случайный доступ.
Так как это относительные значения, но не имеет смысла устанавливать random_page_cost ниже seq_page_cost, однако при применении производительных SSD имеет смысл понизить стоимость обоих значений, чтобы повысить приоритет дисковых операций по отношению к процессорным.
Для производительных SSD можно использовать значения:
seq_page_cost = 0.5random_page_cost = 0.5А для NVme:
seq_page_cost = 0.1random_page_cost = 0.1Но еще раз напомним, данные значения не являются панацеей и должны устанавливаться осмысленно, с реальным пониманием производительности дисковой подсистемы сервера, бездумное копирование настроек способно привести к обратному эффекту.
effective_cache_size = RAM - shared_buffersОпределяет эффективный размер кеша, который может использоваться при одном запросе. Этот параметр не влияет на размер выделяемой памяти, не резервирует ее, а служит для ориентировочной оценки доступного размера кеша планировщиком запросов. Чем он выше, тем большая вероятность использования сканирования по индексу, а не последовательного сканирования. При расчете следует использовать выделенный серверу объем RAM, а не полный объем ОЗУ. В нашем случае это 18 ГБ.
autovacuum = onВключение автовакуума, это очень важный для производительности базы параметр. Не отключайте его!
autovacuum_max_workers = NCores/4..2 но не меньше 4Количество рабочих процессов автовакуума, рассчитывается по числу процессорных ядер, не менее 4, в нашем случае 4.
autovacuum_naptime = 20sВремя сна процессов автовакуума, большое значение будет приводить к неэффективно работе, слишком малое только повысит нагрузку без видимого эффекта.
row_security = offОтключает политику защиты на уровне строк, данная опция не используется платформой и ее отключение дает некоторое повышение производительности.
max_locks_per_transaction = 256Максимальное количество блокировок в одной транзакции, рекомендация от 1С.
escape_string_warning = offstandard_conforming_strings = offДанные опции специфичны для 1С и регулируют использование символа для экранирования.
Сохраним файл конфигурации и перезапустим PostgreSQL, в Linux это можно выполнить командами:
pg-setup service stoppg-setup service startВ Windows штатными средствами операционной системы, либо скриптами из поставки сборки PostgreSQL:
 После чего снова выполним тестирование производительности, на этот раз мы получили следующий результат:
После чего снова выполним тестирование производительности, на этот раз мы получили следующий результат:
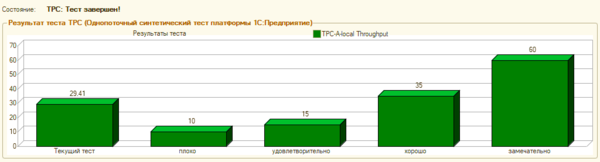 Как видим, достаточно несложные действия по оптимизации добавили серверу около 30% производительности, субъективные ощущения от работы с конфигурацией Розница также повысились, исчезло ощущение «задумчивости», повысилась отзывчивость системы.
Как видим, достаточно несложные действия по оптимизации добавили серверу около 30% производительности, субъективные ощущения от работы с конфигурацией Розница также повысились, исчезло ощущение «задумчивости», повысилась отзывчивость системы.
Указанные выше настройки и параметры являются базовым набором для оптимизации PostgreSQL при совместной работе с 1С:Предприятие и доступны даже начинающим администраторам. Для выполнения этих действий не требуется глубокого понимания работы СУБД, достаточно просто правильно рассчитать ряд значений. Данные рекомендации основаны на официальных и рекомендуются в качестве базовой настройки сервера СУБД сразу после инсталляции.
Используемые источники:
- https://programmist1s.ru/ustanovka-postgresql-1s/
- https://try2fixkb.ru/software/1c_and_postresql_full
- https://interface31.ru/tech_it/2020/03/optimizaciya-proizvoditel-nosti-postgresql-dlya-raboty-s-1spredpriyatie.html

 База знаний
Try 2 Fix beta
База знаний
Try 2 Fix beta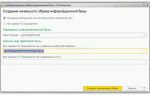 Как в 1С настроить список информационных баз (бесплатная статья по Программированию в 1С)
Как в 1С настроить список информационных баз (бесплатная статья по Программированию в 1С) Заметки разработчика
Заметки разработчика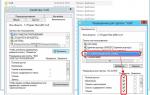 Настройка и использование веб-браузеров
Настройка и использование веб-браузеров